
MSA 환경에서 이벤트 기반 아키텍처(EDA)를 적용할때 Kafka가 주로 사용되곤 한다.
카프카 Consumer 메시지 처리 실패시 dead-letter를 어떻게 관리하고 재시도 전략을 수립하면 좋을지 깊게 고찰해보자. (잘못된 내용 및 피드백은 코멘트로 남겨주시면 최대한 빠르게 확인해보겠습니다😃)
가장 간단하게는 spring-kafka에서 제공하는 DefaultErrorHandler와 DeadLetterPublishingRecoverer를 활용하여 재시도 전략을 고민해볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Bean
public DeadLetterPublishingRecoverer deadLetterPublishingRecoverer() {
return new DeadLetterPublishingRecoverer(kafkaTemplate(), (r, e) -> new TopicPartition(deadLetterTopic, 0));
}
@Bean
public DefaultErrorHandler defaultErrorHandler() {
ExponentialBackOff backOff = new ExponentialBackOff();
backOff.setMaxAttempts(3); // 최대 재시도 횟수
backOff.setInitialInterval(1000L); // 초기 재시도 간격
backOff.setMultiplier(2.0); // 재시도 간격 배수
backOff.setMaxInterval(10000L); // 최대 재시도 간격
return new DefaultErrorHandler(deadLetterPublishingRecoverer(), backOff);
}
하지만 해당 위 방안은 치명적인 문제가 존재한다. 재처리 과정에서 컨슈머의 이후 메시지 처리가 블로킹됨으로써 메시지 처리 지연 현상이 발생하게 된다.
만약 프로듀서 애플리케이션에서 동시에 1000개의 메시지가 발행되었고, 컨슈머 로직의 코드결함으로 모든 메시지 처리에 문제가 발생했다고 가정해보자.
카프카 컨슈머는 하나의 dead-letter 메시지를 Retry 하는데 총 8초가 걸린다. 그렇게 될 경우 1000개의 메시지를 처리하는데 8000초가 걸릴 것이다.
예제 프로젝트의 컨슈머 코드를 다음과 같이 수정후 10개의 메시지를 발행해보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
@KafkaListener(topics = "${spring.kafka.topic.order-event}")
public void consume(ConsumerRecord<String, KafkaOrderEventDto> consumerRecord,
Acknowledgment acknowledgment) {
String topic = consumerRecord.topic();
String key = consumerRecord.key();
KafkaOrderEventDto value = consumerRecord.value();
log.info("[Kafka][Consumer] Topic: {}, Partition: {}, Value: {}", topic, consumerRecord.partition(), value);
throw new RuntimeException();
// orderEventHandler.handle(value);
// acknowledgment.acknowledge();
}
결과는 아래 이미지와 같이 메시지 한 개를 처리하는데 약 8초가 소요되며 메시지 처리 지연 현상이 발생하는 것을 확인할 수 있다.
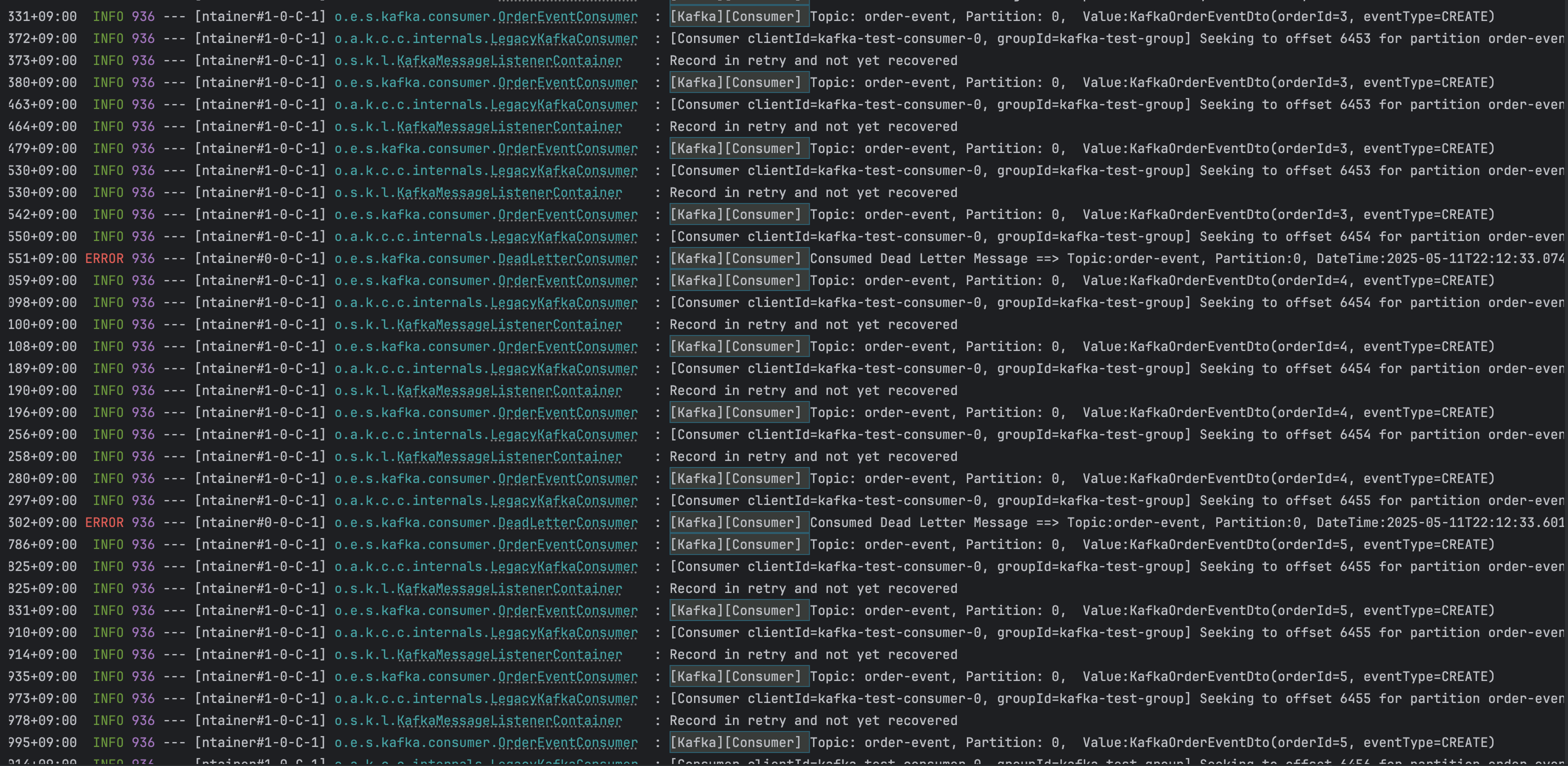
dead-letter 발생 시나리오
dead-letter 발생 및 재처리 시나리오에 대해 살펴보자.(실제로는 더 다양한 케이스들이 존재할 것이다)
- 1. 컨슈머 로직의 코드 결함
- 컨슈머 로직의 코드 결함을 해결후 해당 메시지는 재처리가 가능할 것이다.
- 2. 컨슈머 로직 정상 & Zero-Payload 방식에서 외부 서비스의 결함
- 외부 서비스의 결함(코드결함, 슬로우 쿼리 등)을 해결후 해당 메시지는 재처리가 가능할 것이다.
- 3. 컨슈머 로직 정상 & Zero-Payload 방식에서 외부 서비스가 셧다운된 경우
- 외부 서비스가 다시 복구된후 해당 메시지는 재처리가 가능할 것이다.
- 4. 컨슈머 로직 정상 & DB 장애
- DB가 복구된후 해당 메시지는 재처리가 가능할 것이다.
위 케이스들중 1, 2번은 수동 조치 및 복구의 과정이 필요할 것이며, 3, 4번은 자동 재처리를 적용해볼 수 있을것이다.
dead-letter 관리 및 재시도 전략
위의 내용들을 고려하여 다음과 같은 2가지 dead-letter 관리 및 재시도 전략을 고려해볼 수 있을 것 같다.
1. 컨슈머 로직 실패시 Retry 없이 단일 dead-letter 토픽으로 메시지를 발행 및 컨슘후 별도 DB에 관리하여 개발자가 확인후 수동으로 백오피스 api를 통해 복구
dead-letter 메시지를 개발자가 확인후 수동으로 복구하는 방안이다. 개발자가 확인후 조치할 수 있도록 알림이 필수적으로 적용되야 한다.
Note: 만약 애플리케이션이 사용중인 DB와 dead-letter 를 같은 스토리지에서 관리할 경우, DB 셧다운이 발생하면 dead-letter 메시지가 유실될 수 있다는 점을 유의해야 한다.
2. RetryTopicConfiguration 을 활용하여 Retry 할 수 있는 예외와 토픽을 식별후, 메시지 처리 지연 현상이 발생하지 않도록 비동기적으로 Retry 적용
- Retry 할 수 있는 토픽으로는 비즈니스 중요도에 따라 식별될 수 있을 것이다.
- Retry 할 수 있는 예외로는 일시적인 네트워크 문제 및 DB, 외부 서비스 셧다운 등이 있을 것이다.
- 원본 Exception 을 래핑한 KafkaConsumer 계층의 예외로 던지는 구조가 될 것이다.
RetryTopicConfiguration을 활용하면 메시지 처리 지연 현상을 방지하면서 비동기적으로 Retry를 적용할 수 있다.
정리
Kafka DeadLetter 관리 및 재처리 방안에 대해 정리해보았다.
Kafka DeadLetter Retry는 메시지 소비 지연 현상이 발생하지 않도록 유의해야하고, Retry 할 수 있는 예외를 식별후 비동기적으로 별도 스레드에서의 Retry 처리가 고려되야 한다.