카프카 컨슈머 Lag이란?
- 운영함에 있어 아주 중요한 모니터링 지표 중 하나

- 만약 프로듀서가 데이터를 넣는 속도보다 컨슈머가 가져가는 속도보다 빠르게 된다면?
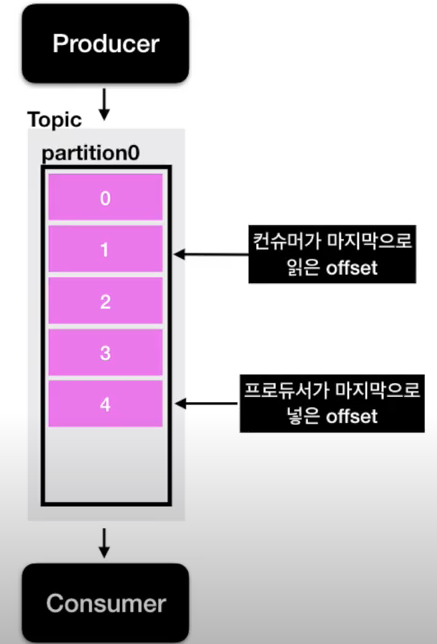
- 프로듀서가 넣은 데이터의 오프셋, 컨슈머가 가져간 데이터의 오프셋간의 차이가 발생함, 이를 lag이라함
- 이 lag의 숫자를 통해 현재 해당 토픽에 대한 파이프라인으로 연계되어 있어는 프로듀서와 컨슈머의 상태를 유추 가능
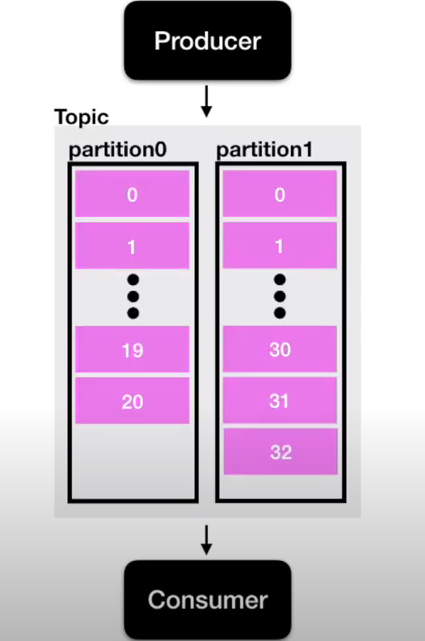
- Topic에 여러 파티션이 존재하게 된다면 lag이 여러 개 존재하게 될 수도 있음
- 만약 컨슈머 그룹이 1개이고 파티션이 2개인 토픽에서 데이터를 가져간다면 Lag은 두 개가 측정 될 수 있음
- 그 중 높은 숫자의 Lag을 records-lag-max라고 부름
- 컨슈머가 성능이 안나오거나 비정상동작을 하게 되면 lag이 필연적으로 발생하기 때문에 주의 깊게 살펴볼 필요가 있음
- 프로듀서가 넣은 데이터의 오프셋, 컨슈머가 가져간 데이터의 오프셋간의 차이가 발생함, 이를 lag이라함
- lag은 두 가지만 알고 넘어가면 됨
- lag은 프로듀서의 오프셋과 컨슈머의 오프셋간의 차이이다
- lag은 여러 개가 존재 할 수 있다
- lag은 프로듀서의 오프셋과 컨슈머의 오프셋간의 차이이다
Lag을 모니터링하기 위해 오픈소스인 Burrow를 사용해야 하는 이유
- Kafka-client 디펜던시 추가 후 KafkaConsumer객체를 통해 현재Lag정보를 가져 올 수 있음
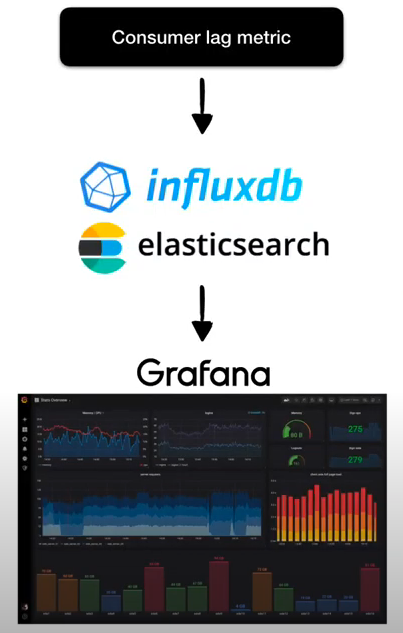
- 만약 Lag을 실시간으로 모니터링하고 싶다면 데이터를 엘라스틱서치나 InfluxDB와 같은 저장소에 넣은 뒤 Grafana 대시보드를 통해 확인 할 수도 있음
- 하지만 컨슈머 단위에서 lag을 모니터링 한다는 것은 아주 위험하고 운영요소가 많이 들어가게 됨
- 왜냐하면 컨슈머 로직 단위에서 lag을 수집한다는 것은 컨슈머 상태에 디펜던시가 걸리기 때문
- 컨슈머가 비정상적으로 종료된다면 컨슈머는 lag정보를 보낼 수 없기 때문에 더 이상 측정불가하게됨
- 추가적으로 컨슈머가 개발될때마다 해당 컨슈머에 lag정보를 특정 저장소에 저장할 수 있도록 로직을 개발해야됨
- 만약 컨슈머lag을 수집할 수 없는 컨슈머라면 lag을 모니터링 할 수 없으므로 운영이 매우 까다로워지게 됨
- 이러한 이유로 링크드인에서는 아파치 카프카와 함께 카프카의 컨슈머lag을 효과적으로 모니터링 할 수 있도록 Burrow를 오픈 소스로 제공
Burrow란?
- 컨슈머lag모니터링을 도와주는 독립적인 어플리케이션, 많은 기업들에서 사용중에 있음
- Burrow의 세 가지 큰 특징
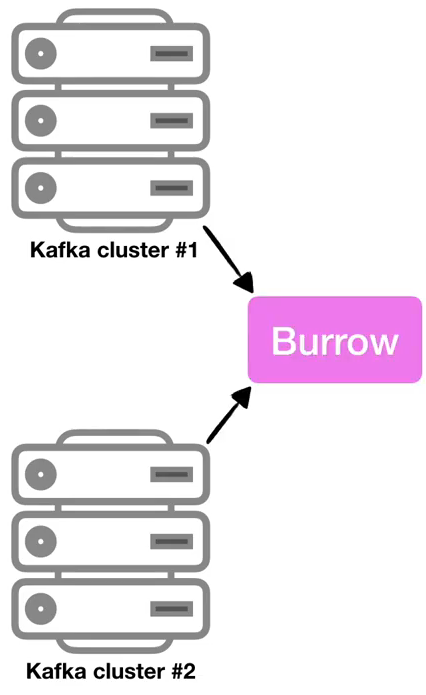
- 1) 멀티 카프카 클러스터 지원
- 대부분의 기업들은 2개 이상의 카프카 클러스터를 운영
- 이렇게 카프카 클러스터가 여러 개더라도 Burrow application 1개만 실행해서 연동한다면 카프카 클러스터들에 붙은 컨슈머의 lag을 모두 모니터링할 수 있음
- 대부분의 기업들은 2개 이상의 카프카 클러스터를 운영
- 2) Sliding window를 통한 Consumer의 status 확인
- ‘Error’, ‘WARNING’, ‘OK’로 컨슈머의 status를 표현
- 만약 데이터양이 일시적으로 많아져서 consumer offset이 증가되고 있으면 ‘WARNING’
- 만약 데이터양이 많아지고 있는데 Consumer가 가져가지 않으면 ‘ERROR’
- ‘Error’, ‘WARNING’, ‘OK’로 컨슈머의 status를 표현
- 3) HTTP api 제공
- 위와 같은 정보들은 HTTP api를 통해 조회 가능
- response받은 데이터를 시계열DB와 같은 곳에 저장하는 application을 구축해서 활용할수도 있음
출처
- 위와 같은 정보들은 HTTP api를 통해 조회 가능
- 1) 멀티 카프카 클러스터 지원
- https://www.youtube.com/watch?v=b3i6D4eeBGw&list=PL3Re5Ri5rZmkY46j6WcJXQYRlDRZSUQ1j&index=10
- https://freedeveloper.tistory.com/351