
페치 조인의 한계
1) 페치 조인 대상에는 별칭(alias)을 줄 수 없다.
1
2
String query = "select t from Team t join fetch t.members as m"
//as m 이라는 별칭(alias)는 fetch join에서 사용할 수 없다.
- 하이버네이트는 가능하지만, 가급적 사용을 하지 않는게 좋다
- ex: 팀을 조회하는 상황에서 멤버가 5명인데 3명만 조회한 경우 3명만 따로 조작하는 것은 몹시 위험.하다.
1
String query = "select t from Team t join fetch t.members as m where m.age > 10"
- 기본적으로 JPA에서 설계사상은 객체 그래프를 탐색한다는 것은 연관된 엔티티를 모두 가져온다는 것을 가정하고 만들어졌다.
- fetch join에 별칭을 붙히고 where절을 더해 필터해서 결과를 가져오게 되면 모든걸 가져온 결과와 비교하여 다른 갯수에 대해서 정합성을 보장하지 않는다.
- 하이버네이트는 가능하지만 가급적 사용하지 않는게 좋다.
2) 둘 이상의 컬렉션은 페치 조인 할 수 없다.
1
2
String query = "select t from Team t join fetch t.members, t.orders"
//불가능 fetch join에서 컬렉션은 1개만 사용하자.
- 데이터 정합성에 안맞는다.
- 잘못하면 데이터가 예상치 못하게 팍팍 늘어나면서 곱하기 곱하기가 될 수 있다.
딱 하나만 지정할 수 있다.
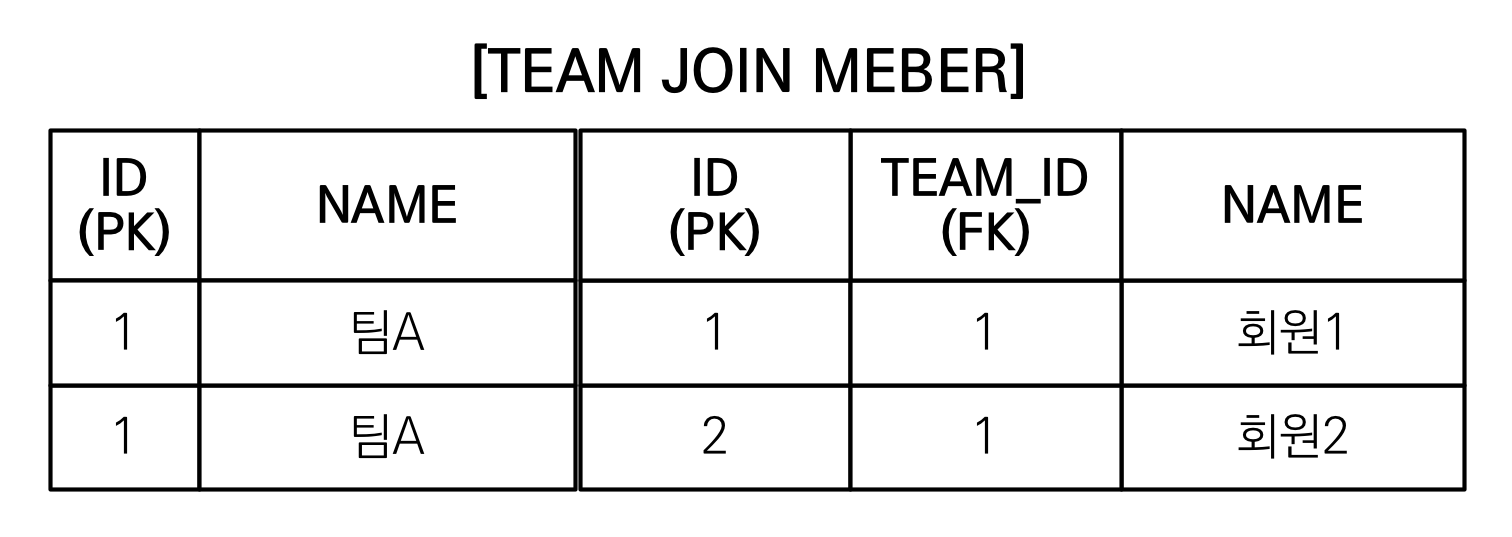
3) 컬렉션(일대다)을 페치 조인하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없다.

- 만약 여기서 페이징이 적용되면 회원1만 남게된다. 그러면 팀A는 회원1만 가지고 있는걸로 되버린다. 문제가 있다.
- 일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능
- 하이버네이트는 경고 로그를 남기고 메모리에서 페이징(매우 위험)
실제 쿼리에 페이징 구문이 없다? -> 팀이 100만건이면 100만건을 다 메모리에 올리고 페이징한다. 바로 그냥 망한다.
- 세 가지 해결법이 있다.
- 1)회원에서 팀으로 방향을 반대로 뒤집어 해결하는 방법이 있다.
1 2 3 4 5
String query = "select m from Member m join fetch m.team t"; List<Member> result = em.createQuery(query, Member.class) .setFirstResult(0) .setMaxResults(1) .getResultList();- 2)
@BatchSize(size = 100)을 지정하여 해결할 수 가 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
@Entity public class Team { @Id @GeneratedValue private Long id; private String name; @BatchSize(size = 100) @OneToMany(mappedBy = "team") private List<Member> members = new ArrayList<>(); ... } public class JpaMain { public static void main(String[] args) { ... String query = "select t from Team t"; List<Team> result = em.createQuery(query, Team.class) .setFirstResult(0) .setMaxResults(2) .getResultList(); System.out.println("result.size() = " + result.size()); for (Team team : result) { System.out.println("team = " + team.getName() + " | " + team.getMembers().size()); for (Member member : team.getMembers()) { System.out.println("- members = " + member); } } tx.commit(); } } SQL: Hibernate: /* load one-to-many jpql.Team.members */ select members0_.TEAM_ID as team_id5_0_1_, members0_.id as id1_0_1_, members0_.id as id1_0_0_, members0_.age as age2_0_0_, members0_.TEAM_ID as team_id5_0_0_, members0_.type as type3_0_0_, members0_.username as username4_0_0_ from Member members0_ where members0_.TEAM_ID in ( ?, ? )- 처음에 Team테이블 select 쿼리 1번 + List결과에 담긴 Team객체를 100개씩 in절에 담아 members객체에 채워넣는다.
- global 세팅으로 가져갈 수 있다.
1
<property name="hibernate.default_batch_fetch_size" value="100" />
- 3)DTO로 쿼리 직접 짜는 방법(DTO로 뽑아도 정제해줘야하기에 만만치 않다)
출처
JPQL의 distinct
- JPQL의 distinct는 두 가지 역할을 한다.
- 1)SQL에 distinct를 추가하는 역할
- 2)애플리케이션에 중복된 객체들을 제거하는 역할
출처
플러시
- 플러시는 영속성 컨텍스트의 변경 내용을 DB에 반영한다.
- 트랜잭션 커밋이 일어날 떄 플러시가 동작하는데, 쓰기 지연 저장소에 쌓아 놨던 insert, update, delete 쿼리들이 DB에 날라간다.
- 쉽게 얘기해서 영속성 컨텍스트의 변경사항들과 DB를 싱크(동기화)하는 작업이다.
플러시 발생
- 플러시가 발생하면 어떤 일이 생기나?
- 변경을 감지한다. Dirty Checking
- 수정된 엔티티를 쓰기 지연 SQL 저장소에 등록한다.
- 쓰기 지연 SQL 저장소의 쿼리를 DB에 전송한다.(등록, 수정, 삭제 쿼리)
- 플러시가 발생한다고 커밋이 이루어지는게 아니고, 플러시 다음에 커밋이 일어난다.
영속성 컨텍스트를 플러시하는 방법
em.flush()로 직접 호출
1
2
3
4
5
6
7
8
9
// 영속
Member member = new Member(200L, "A");
em.persist(member);
em.flush();
System.out.println("플러시 직접 호출하면 쿼리가 커밋 전 플러시 호출 시점에 나감");
transaction.commit();
트랜잭션 커밋시 플러시 자동 호출JPQL 쿼리 실행시 플러시 자동 호출- JPQL 쿼리 실행시 플러시가 자동으로 호출되는 이유는
- 아래와 같이 member1,2,3을 영속화한 상태에서. 쿼리는 안날라간 상태
- JPQL로 SELECT 쿼리를 날리려고 하면 저장되어 있는 값이 없어서 문제가 생길 수 있다.
- JPA는 이런 상황을 방지하고자 JPQL 실행 전에 무조건 flush()로 DB와의 싱크를 맞춘 다음에 JPQL 쿼리를 날리도록 설정 되어 있다.
- 그래서 아래의 상황에서는 JPQL로 멤버들을 조회할 수 있다.
1 2 3 4 5 6 7
em.persist(memberA); em.persist(memberA); em.persist(memberA); // 중간에 JPQL 실행 query = em.createQuery("select m from Member m", Member.class); List<Member> members = query.getResultList();
플러시가 일어난다 해도 1차 캐시가 삭제되지 않는다. 쓰기 지연 SQL 저장소에 있는 쿼리들만 DB에 전송되고 1차 캐시는 남아있다.
플러시 모드 옵션
em.setFlushMode(FlushModeType.COMMIT);- FlushModeType.AUTO: 커밋이나 쿼리 실행시 플러시(기본값)
- FlushModeType.COMMIT: 커밋 할때만 플러시
플러시 정리
- 플러시는 영속성 컨텍스트를 비우지 않는다. 절대 오해하면 안된다.
- 플러시는 영속성 컨텍스트의 변경 내용을 DB에 동기화 한다.
- 플러시가 동작할 수 있는 이유는 DB에 트랜잭션이라는 작업 단위(개념)가 있기 때문이다.
- 어쨋든 트랜잭션이 시작되고 커밋되는 시점에만 동기화 해주면 되기 때문에, 그 사이에서 플러시 매커니즘의 동작이 가능한 것이다.
- JPA는 기본적으로 데이터를 맞추거나 동시성에 관련된 것들은 DB 트랜잭션에 위임한다. 참고로 알아두자.
em.clear() 는 영속성 컨텍스트에 저장한 데이터를 지워버린다.(초기화 한다)
출처
QueryDSL과 JPQL 차이점
QueryDSL은 JPQL빌더 역할을 한다.(결국엔 jpql로 변환된다)
출처
@DynamicUpdate
Dirty Checking으로 생성되는 update 쿼리는 기본적으로 모든 필드 를 업데이트한다.
JPA에선 전체 필드를 업데이트하는 방식을 기본값으로 사용한다. 전체 필드를 업데이트하는 방식의 장점은 다음과 같다.
- 생성되는 쿼리가 같아 부트 실행시점에 미리 만들어 재사용 가능한다.
- DB 입장에선 쿼리 재사용이 가능하다.(동일한 쿼리를 받으면 이전에 파싱된 쿼리를 재사용하기에)
다만, 필드가 20~30개 이상인 경우엔 이런 전체 필드 Update 쿼리가 부담스러울 수 있다.
사실 이런 경우 정규화가 잘못된 경우일 확률이 높다. 한 테이블에 필드 30개는 확실히 많다.
그래서 이런 경우엔 @DynamicUpdate로 변경 필드만 반영되도록 할 수 있다.
엔티티 최상단에 아래와 같이 @DynamicUpdate를 선언해주시면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
@Getter
@NoArgsConstructor
@Entity
@DynamicUpdate // 변경한 필드만 대응
public class Pay {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String tradeNo;
private long amount;
}
그러면 변경된 부분만 Update쿼리를 날리게 된다.