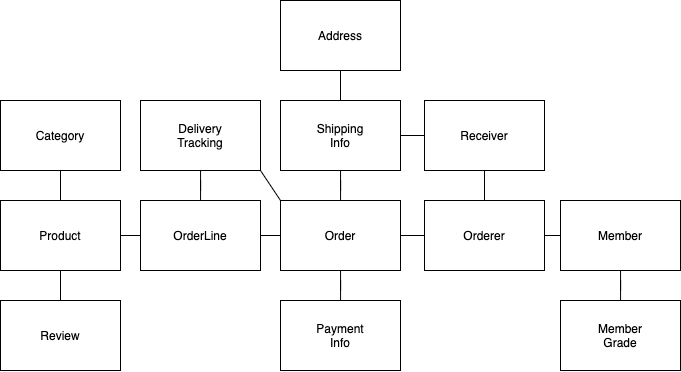
애그리거트

- 백 개이상의 테이블을 한장의 ERD에 모두 표시하면 개별 테이블 간의 관계를 파악하느라 큰 틀에서 데이터 구조를 이해하는데 어려움을 겪게 되는 것처럼, 도메인 객체 모델이 복잡해지면 개별 구성요소 위주로 모델을 이해하게 되고 전반적인 구조나 큰 수준에서 도메인 간의 관계를 파악하기 어려워진다.
- 주요 도메인 개념 간의 관계를 파악하기 어렵다는 것은 곧 코드를 변경하고 확장하는 것이 어려줘진다는 것을 의미한다.
- 상위 수준에서 모델이 어떻게 엮여 있는지 알아야 전체 모델을 망가뜨리지 않으면서 추가 요구사항을 모델에 반영할 수 있는데 세부적인 모델만 이해한 상태론 코드를 수정하기가 두렵기 때문에 코드 변경을 최대한 회피하는 쪽으로 요구사항을 협의하게 된다.
- 꼼수를 부려 당장 돌아가는 코드를 추가할 순 있지만 이는 장기적인 관점에서 코드를 더 수정하기 어렵게 만들기도 한다.
- 복잡한 도메인을 이해하고 관리하기 쉬운 단위로 만들려면 상위 수준에서 모델을 조망할 수 있는 방법이 필요한데, 그 방법이 애그리거트이다.
- 앞선 쳅터에서 언급한 것처럼 애그리거트는 관련된 객체를 하나의 군으로 묶어준다.
애그리거트가 가지는 책임
- 위 이미지에서 본 것처럼 애그리거트는 경계를 갖는다.
- 한 애그리거트에 속한 객체는 다른 애그리거트에 속하지 않는다. 즉 독립된 객체 군이며, 각 애그리거트는 자기 자신을 관리할 뿐 다른 애그리거트를 관리하지 않는다.
- 예를 들어, 주문 애그리거트는 배송지를 변경하거나 주문 상품 개수를 변경하는 등 자기 자신을 관리하지만, 회원의 비밀번호를 변경하거나 상품의 가격을 변경하진 않는다.
애그리거트의 경계를 어떻게 나누느냐
- 경계를 설정할 때 기본이 되는 것은 도메인 규칙과 요구사항이다.
- 도메인 규칙에 따라 함께 생성되는 구성요소는 한 애그리거트에 속할 가능성이 높다.
- 예를 들어, 주문할 상품 개수, 배송지 정보, 주문자 정보는 주문 시점에 함께 생성되므로 이들은 한 애그리거트에 속한다.
- 또한, OrderLine의 주문 상품 개수를 변경시 도메인 규칙에 따라 Order의 총 주문 금액도 새로 계산해야 한다.
- 사용자 요구사항에 따라 주문 상품 개수와 배송지를 함께 변경하기도 한다.
- 이렇게 하면 함께 변경되는 비녿가 높은 객체는 한 애그리거트에 속할 가능성이 높다.
- 흔히 ‘A가 B를 갖는다’ 로 설계할 수 있는 요구사항이 있다면 A와 B를 한 애그리거트로 묶어서 생각하기 쉽다.
- 주문의 경우 Order가 ShippingInfo와 Orderer를 가지므로 이는 어느 정도 타당해 보인다.
- 하지만 ‘A가 B를 갖는다’로 해석할 수 있는 요구사항이 있따하더라도 이것이 반드시 A와 B가 한 애그리거트에 속한다는 것을 의미하는 것은 아니다.
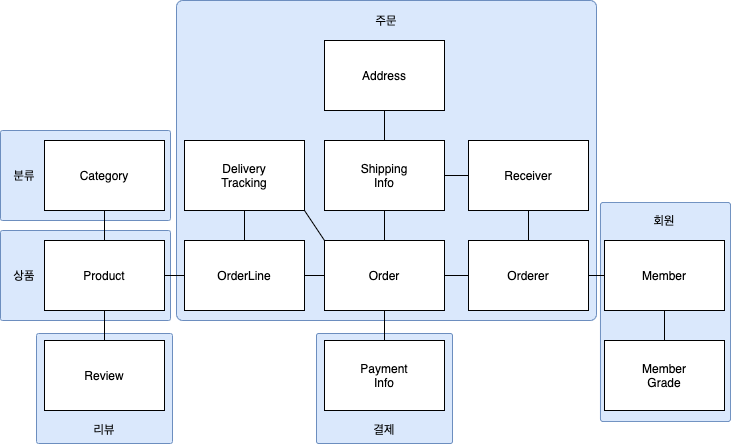
- 좋은 예가 상품과 리뷰다. 상품 상세 페이지에 들어가면 상품 상세 정보와 함꼐 리뷰 내용을 보여줘야 한다는 요구사항이 있다면 Product 엔티티와 Review엔티티가 한 애그리거트에 속한다 생각할 수 있지만 이 둘은 함께 생성되지 않고 함께 변경되지 않는다.
- 게다가 Product 를 변경하는 주체가 상품 담당자라면 Review를 생성하고 변경하는 주체는 고객이다.
- Review의 변경이 Product에 영향을 주지 않고 반대로 Product의 변경이 Review에 영향을 주지 않기 떄문에 이 둘은 한 애그리거트에 속한다기보다는 [그림 3.3]에 표시한 것처럼 서로 다른 애그리거트에 속한다.
- 처음 도메인 모델을 만들기 시작하면 큰 애그리거트로 보이는 것들이 많지만 도메인에 대한 경험이 생기고 도메인 규칙을 제대로 이해할수록 실제 애그리거트의 크기는 줄어들게 된다.
- 저자의 경험을 비추어보면 다수의 애그리거트가 한 개의 엔티티 객체만 갖는 경우가 많으며 두 개 이상의 엔티티로 구성되는 애그리거트는 드물게 존재한다고 한다.
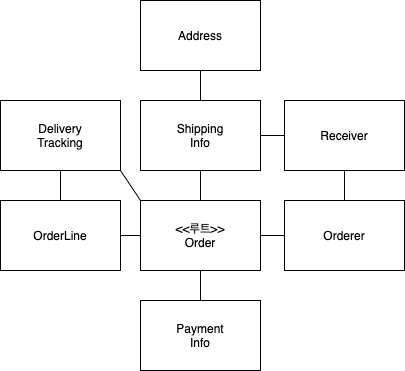
애그리거트 루트
- 애그리거트는 여러 객체로 구성되기 때문에 반드시 모든 객체들의 상태가 정상이어야 한다.
- 예를 들어, 개별 구매 상품의 개수인 quantity와 금액 price를 가지는 OrderLine과 Order 객체의 총 주문 금액 totalAmounts 는 정합성이 맞아들어야 한다.
- 애그리거트에 속한 모든 객체가 일관된 상태를 유지하려면 애그리거트 전체를 관리할 주체가 필요한데 이 책임을 지는 것이 바로 애그리거트의 루트 엔티티다.
- 위 이미지에선 Order 가 애그리거트 루트 역할을 한다 볼 수 있다.
도메인 규칙과 일관성
- 애그리거트 루트의 핵심 역할은 애그리거트의 일관성이 깨지지 않도록 하는 것이다.
- 이를 위해 애그리거트 루트는 애그리거트가 제공해야 할 도메인 기능을 구현한다.
- 예를 들어, 주문 애그리거트는 배송지 변경, 상품 변경과 같은 기능을 제공하는데 Order가 이 기능을 구현한 메서드를 제공한다.
- 애그리거트 루트가 제공하는 메서드는 도메인 규칙에 따라 애그리거트에 속한 객체의 일관성이 깨지지 않도록 구현해야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class Order{
// 애그리거트 루트는 도메인 규칙을 구현한 기능을 제공한다.
public void changeShippingInfo(ShippingInfo newShippingInfo) {
verifyNotYetShipped(); // 출고 전에만 배송지 변경을 할 수 있다는 규칙을 구현
setShippingInfo(newShippingInfo);
}
private void verifyNotYetShipped(){
if(state != OrderState.PAYMENT_WAITING && state != OrderState.PREPARING)
throw new IllegalStateException("already shippped");
}
...
}
|
- 애그리거트 루트가 아닌 다른 객체가 애그리거트에 속한 객체를 직접 변경하면 안된다.
- getter를 무분별하게 만들었을 때 발생하는 문제점 중 하나이다.
- 이는 애그리거트 루트가 강제하는 규칙을 적용할 수 없어 모델의 일관성을 깨는 원인이 된다.
1
2
| ShippingInfo si = order.getShippingInfo();
si.setAddress(newAddress);
|
- 위 코드는 주문 상태와 관계 없이 배송지 주소를 변경하게 되는데 논리적인 데이터 일관성이 꺠지게 된다.
- 일관성을 지키기 위해 상태 확인 로직을 응용 서비스에서 구현할 수 도 있지만, 이렇게 되면 동일한 검사 로직을 여러 응용 서비스에서 중복 구현할 가능성이 높아져 상황을 더 악화시킬 수 있다.
- 유지보수성이 떨어지게되고 막 예시를 들어 주소 변경 도메인 규칙이 추가되거나 변경될 경우 일일이 다 찾아서 처리를 해줘야 될 것이다..
1
2
3
4
5
6
7
| ShippingInfo si = order.getShippingInfo();
// 주요 도메인 로직이 중복되는 문제
if(state != OrderState.PAYMENT_WAITING && state != OrderState.PREPARING)
throw new IllegalStateException("already shippped");
si.setAddress(newAddress);
|
불필요한 중복을 피하고 애그리거트 루트를 통해서만 도메인 로직을 구현하게 만들기 위한 두 가지 습관
1. 단순히 필드를 변경하는 set메서드를 공개 (public) 범위로 만들지 않는다.
1
2
3
4
| // 도메인 모델에서 공개 set 메서드는 가급적 피해야 한다.
public void setName(String name) {
this.name = name;
}
|
- 공개 set 메서드는 중요 도메인의 의미나 의도를 표현하지 못하고 도메인 로직이 도메인 객체가 아닌 응용 표현 영역으로 분산되게 만드는 원인이 된다.
- 도메인 로직이 한 곳에 응집되어 있지 않게 되므로 코드를 유지보수할 때에도 분석하고 수정하는데 더 많은 시간을 들이게 된다.
- 도메인 모델의 엔티티나 밸류에 공개 set 메서드만 넣지 않아도 이로간성이 깨질 가능성이 줄어든다.
- 공개 set 메서드를 사용하지 않게 되면 의미가 드러나는 메서드를 사용해서 구현할 가능성이 높아진다.
- 예를 들어, set 형식의 이름을 갖는 공개 메서드를 사용하지 않으면 자연스럽게 cancel이나 changePassword 처럼 의미가 더 잘 드러나는 이름을 사용하는 빈도가 높아진다.
2. 벨류 타입은 불변으로 구현한다.
- 밸류 객체의 값을 변경할 수 없으면 애그리거트 루트에서 밸류 객체를 구해도 값을 변경할 수 없기에 애그리거트 외부에서 밸류 객체의 상태를 변경할 수 없게 된다.
1
2
3
| ShippingInfo si = order.getShippingInfo();
si.setAddress(newAddress); // ShippingInfo 벨류 객체가 불변이면 컴파일 에러 발생!
|
- 애그리거트 외부에서 내부 상태를 함부로 바꾸지 못하므로 애그리거트의 이로간성이 꺠질 가능성이 줄어든다.
- 즉, 다음과 같이 애그리거트 루트가 제공하는 메서드에 새로운 벨류 객체를 적달해서 값을 변경하는 방법 밖에 없다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class Order{
public void changeShippingInfo(ShippingInfo newShippingInfo) {
verifyNotYetShipped();
setShippingInfo(newShippingInfo);
}
// set 메서드의 접근 허용 범위는 private이다.
private void setShippingInfo(ShippingInfo shippingInfo) {
// 벨류가 불변이면, 새로운 객체를 할당해서 값을 변경해야 한다.
// 불변이므로 this.shippingInfo.setAddress(newShippingInfo.getAddress())와 같은 코드를 사용할 수 없다.
this.shippingInfo = shippingInfo;
}
}
|
애그리거트 루트의 기능 구현
- 애그리거트 루트는 애그리거트 내부의 다른 객체를 조합해서 기능을 완성한다.
- 예를 들어, Order는 총 주문 금액을 구하기 위해 OrderLine 목록을 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
| public class Order {
private Money money;
private List<OrderLine> orderLines;
private void calculateTotalAmounts() {
int sum = orderLine.stream()
.mapToInt(o1 -> o1.getPrice() * o1.quantity())
.sum();
this.totalAmounts = new Money(sum);
}
}
|
- 또한 기능 실행을 위임하기도 한다.
- Order의 changeOrderLines() 메서드는 내부의 orderLines 필드에 상태변경을 위임하는 방식으로 구현한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class Order {
private OrderLines orderLines;
private void changeOrderLines(List<OrderLine> newOrderLines) {
orderLines.changeOrderLines(newOrderLines);
this.totalAmounts = orderLines.getTotalAmounts;
}
}
public class OrderLines {
private List<OrderLine> lines;
public Money getTotalAmounts() {
...
};
private void changeOrderLines(List<OrderLine> newLines) {
this.lines = newLines;
}
}
|
- 만약 Order가 getOrderLines()와 같이 OrderLine를 구할 수 있는 메서드를 제공하면 애그리거트 외부에서 OrderLines의 기능을 실행할 수 있게 된다.
1
2
3
4
5
| OrderLines lines = order.getOrderLines();
// 외부에서 애그리거트 내부 상태 변경!
// order의 totalAmounts가 값이 OrderLines가 일치하지 않게 됨
lines.changeOrderLines(newOrderLines);
|
- 이 코드는 주문의 OrderLine 목록이 바뀌는데 총합은 계산하지 않는 버그를 만든다.
- 이런 버그를 생기지 않도록 하려면 애초에 애그리거트 외부에서 OrderLine 목록을 변경할 수 없도록 OrderLines를 불변으로 구현하면 된다.
- 팀 표준이나 구현 기술의 제약으로 OrderLines를 불변으로 구현할 수 없다면 OrderLines의 변경 기능을 패키지나 protected 범위로 한정해서 외부에서 실행할 수 없도록 제한하는 방법이 있다.
- 보통 한 애그리거트에 속하는 모델은 한 패키지에 속하기 때문에 패키지나 protected 범위를 사용하면 애그리거트 외부에서 상태 변경 기능을 실행하는 것을 방지 할 수 있다.
트랜잭션 범위
- 트랜잭션의 범위는 작으면 작을 수록 좋다.
- DB 테이블을 기준으로 한 트랜잭션이 한개의 테이블을 수정하는 것과 세 개의 테이블을 수정하는 것은 성능에서 차이가 발생한다.
- 한 개의 테이블을 수정할 땐 트랜잭션 충돌을 막기 위해 잠그는 대상이 한 개 테이블의 한 행으로 한정되지만, 세 개의 테이블을 수정하면 잠금 대상이 더 많아진다.
- 잠금 대상이 많아진다는 것은 그만큼 동시에 처리할 수 있는 트랜잭션 개수가 줄어든다는 것을 뜻하고 전체적인 성능(처리량)을 떨어뜨린다.
- 동일하게 한 트랜잭션에선 한 개의 애그리거트만 수정해야 한다.
- 한 트랜잭션에서 두 개 이상의 애그리거트를 수정하면 트랜잭션 충돌이 발생할 가능성이 더 높아지기 때문에 한 번에 수정하는 애그리거트 개수가 많아질수록 전체 처리량이 떨어지게 된다.
- 한 트랜잭션에서 한 애그리거트만 수정한다는 것은 애그리거트에서 다른 애그리거트를 변경하지 않는다는 것을 뜻한다.
- 한 애그리거트에서 다른 애그리거트를 수정하면 결과적으로 두 개의 애그리거트를 한 트랜잭션에서 수정하게 되므로 한 애그리거트 내부에서 다른 애그리거트의 상태를 변경하는 기능을 실행하면 안된다.
- 예를 들어, 배송지 정보를 변경하면서 동시에 배송지 정보를 회원의 주소로 설정하는 기능이 있따고 해보자.
- 이 경우 주문 애그리거트는 다음과 같이 회원 애그리거트의 정보를 변경해선 안된다.
1
2
3
4
5
6
7
8
9
10
11
12
| public class Order {
private Orderer orderer;
public void shipTo(ShippingInfo shippingInfo, boolean useNewShippingAddrAsMemberAddr) {
verifyNotYetShipped();
setShippingInfo(newShippingInfo);
if (useNewShippingAddrAsMemberAddr) {
// 다른 애그리거트의 상태를 변경하면 안됨!
order.getOrderer().getCustomer().changeAddress(newShippingInfo.getAddress());
}
}
}
|
- 이는 애그리거트가 자신의 책임 범위를 넘어 다른 애그리거트의 상태까지 관리하는 꼴이 된다.
- 애그리거트는 서로 최대한 독립적이어야 하는데 한 애그리거트가 다른 애그리거트의 기능에 의존하기 시작하면 애그리거트 간의 결합도가 높아지게 된다.
- 결합도가 높아지면 높아질수록 향후 수정 비용이 증가하므로 애거리트에서 다른 애그리거트의 상태를 변경하지 말아야 한다.
- 만약 한 트랜잭션에서 두 개 이상의 애그리거트를 수정해야한다면 아래와 같이 응용 서비스에서 두 애그리거트를 수정하도록 하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class ChangeOrderService {
@Transactional
public void changeShippingInfo(OrderId id,
ShippingInfo newShippingInfo,
boolean useNewShippingAddrAsMemberAddr) {
Order order = orderRepository.findbyId(id);
if (order == null) throw new OrderNotFoundException();
order.shipTo(newShippingInfo);
if (useNewshippingAddrAsMemberAddr) {
order.getOrderer()
.getCustomer().changeAddress(newShippingInfo.getAddress());
}
}
...
}
|
도메인 이벤트를 사용하면 한 트랜잭션에서 한 개의 애그리거트를 수정하면서도 동기나 비동기로 다른 애그리거트의 상태를 변경할 수 있다. 관련된 내용은 10장에서 살펴보자.
기본적으로 한 트랜잭션에서 하나의 애그리거트를 수정하는 것을 권장하지만, 다음의 경우에는 두 개 이상의 애그리거트를 변경하는 것을 고려해볼 수 있다.
- 1)팀 표준 : 조직의 표준에 따라 사용자 유스케이스와 관련된 응용 서비스의 기능을 한 트랜잭션으로 실행해야 하는 경우
- 2)기술 제약 : 한 트랜잭션에서 두 개 이상의 애그리거트를 수정하는 대신 도메인 이벤트와 비동기를 사용하는 방식을 사용하는데, 기술적으로 이벤트 방식을 도입할 수 없는 경우 한 트랜잭션에서 다수의 애그리거트를 수정해서 일관성을 처리해야 한다.
- 3)UI 구현의 편리 : 운영자의 편리함을 위해 주문 목록 화면에서 여러 주문의 상태를 한 번에 변경하고 싶을 경우
리포지터리와 애그리거트
- 리포지터리는 애그리거트 단위로 존재한다,
- Order와 OrderLine을 물리적으로 각각 별도의 DB테이블에 저장한다고 해서 Order 와 OrderLine을 위한 리포지터리를 각각 만들지 않는다. Order가 애그리거트 루트이고 OrderLine인 애그리거트에 속하는 구성요소이므로 Order 를 위한 리포지토리만 존재한다.
- ORM 기술 중의 하나인 JPA/Hibernate 를 사용하면 DB관계형 모델에 객체 도메인 모델을 맞춰야 하는 경우도 있다.
- 특히 레거시 DB를 사용해야 하거나 팀 내 DB 설계 표준을 따라야 한다면 DB 테이블 구조에 맞게 모델을 변경해야 한다.
- 이 경우 밸류 타입인 도메인 모델을(JPA에서 밸류 타입을 매핑할 떄 사용하는) @Component 가 아닌 (엔티티를 매핑할 때 사용하는) @Entity를 이용해야 할 수도 있다.
- 애그리거트는 개념적으로 하나이므로 리포지터리는 애그리거트 전체를 저장소에 영속화해야 한다.
- 예를 들어, Order 애그리거트와 관련된 테이블이 세 개라면 리포지터리를 통해서 Order 애그리거트를 저장할 떄 애그리거트 루트와 매핑되는 테이블뿐만 아니라 애그리거트에 속한 모든 구성요소를 위한 테이블에 데이터를 저장해야 한다.
1
2
| // 리포지토리에 애그리거트를 저장하면 애그리거트 전체를 영속화해야 한다.
orderRepository.save(order);
|
- 위와 동일하게 애그리거트를 구하는 리포지터리 메서드는 완전한 애그리거트를 제공해야 한다.
- 즉 다음 코드를 실행시 order 애그리거트는 OrderLine, Orderer 등 모든 구성요소를 포함하고 있어야 한다.
- 그렇지 않을 경우 NPE 가 발생하게 된다.
1
2
3
4
5
6
| // 리포지토리는 완전한 order를 제공해야 한다.
Order order = orderRepository.findById(orderId);
// order가 온전한 애그리거트가 아니면
// 기능 실행 도중 NPE 가 발생한다.
order.cancel();
|
- 애그리거트를 영속화할 저장소로 무엇을 사용하든지 간에(RDBMS, Mongo DB, HBase) 애그리거트의 상태가 변경되면 모든 변경을 원자적으로 저장소에 반영해야 한다. 데이터 일관성을 보장하는 것이 중요하다.
- RDBMS와 JPA를 이용한 리포지토리와 애그리거트의 구현에 대한 내용은 4장에서 살펴볼 예정이다.
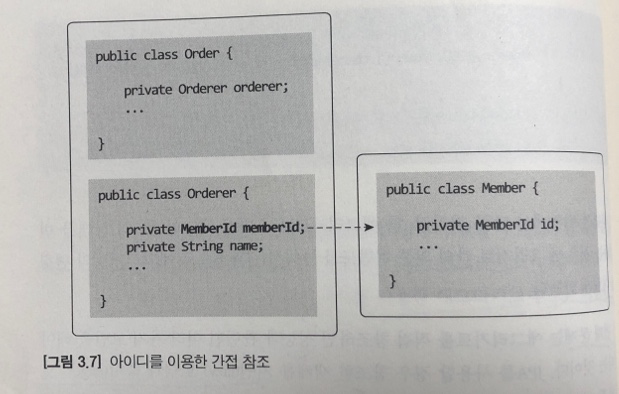
ID를 이용한 애그리거트 참조
- 애그리거트는 다른 애그리거트를 참조한다.
- 애그리거트의 관리 주체가 애그리거트 루트이므로 애그리거트에서 다른 애그리거트를 참조한다는 것은 애그리거트의 루트를 참조한다는 것과 같다.
다른 애그리거트 필드 참조
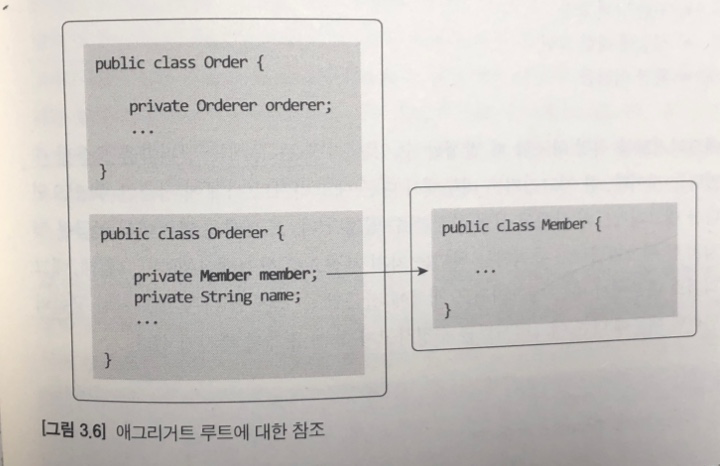
- 예를 들어, 주문 애그리거트에 속해 있는 Orderer 는 [그림 3.6]처럼 주문한 회원을 참조하기 위해 회원 애그리거트 루트인 Member를 필드로 참조할 수 있다.
- 필드를 이용해서 다른 애그리거트를 직접 참조하는 것은 개발자에게 구현의 편리함을 제공한다.
- 예를 들어, 주문 정보 조회 화면에서 회원 아이디를 이용해서 링크를 제공해야 한다고 해보자.
- 이 경우, 다음과 같이 Order로부터 시작해서 회원 아이디를 구할 수 있다.
1
| order.getOrderer().getMember().getId();
|
- JPA를 사용하면
@ManyToOne, @OneToOne 과 같은 어노테이션을 이용해서 연관된 객체를 로딩하는 기능을 제공하고 있으므로 필드를 이용해서 다른 애그리거트를 쉽게 참조할 수 있다.
다른 애그리거트 필드 참조의 문제점
1) 편한 탐색 오용
- 가장 큰 문제점이다.
- 한 애그리거트 내부에서 다른 애그리거트 객체에 접근할 수 있으면 다른 애그리거트의 상태를 쉽게 변경할 수 있게 된다.
- 트랜잭션 범위에서 언급한 것처럼 한 애그리거트가 관리하는 범위는 자기 자신으로 한정해야 한다.
- 그런데, 애그리거트 내부에서 다른 애그리거트 객체에 접근할 수 있으면 다음 코드처럼 구현의 편리함 때문에 다른 애그리거트를 수정하고자 하는 유혹에 빠지기 쉽다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public class Order {
private Orderer orderer;
public void changeShippingInfo(ShippingInfo newShippingInfo,
boolean useNewShippingAddrAsMemberAddr) {
...
if(useNewShippingAddrAsMemberAddr) {
// 한 애그리거트 내부에서 다른 애그리거트에 접근할 수 있으면
// 다른 애그리거트의 상태를 변경하는 유혹에 빠지기 쉽다.
orderer.getCustomer().changeAddress(newShippingInfo.getAddress());
}
...
}
}
|
- 트랜잭션 범위에서 말한 것철검, 한 애그리거트에서 다른 애그리거트의 상태를 변경하는 것은 애그리거트 간의 의존 결합도를 높여서 결과적으로 애그리거트의 변경을 어렵게 만든다.
2) 성능에 대한 고민
- JPA를 사용할 경우 참조한 객체를 지연(Lazy)로딩과 즉시(Eager) 로딩의 두 가지 방식으로 로딩할 수 있다.
- 두 로딩 방식 중 무엇을 사용할지 여부는 애그리거트의 어떤 기능을 사용하느냐에 따라 달라진다.
- 단순히 연관된 객체의 데이터를 함께 보여주어야 하면 즉시 로딩이 조회성능에 유리하지만, 애그리거트의 상태를 변경하는 기능을 실행하는 경우엔 불필요한 객체를 함꼐 로딩할 필요가 없으므로 지연 로딩이 유리하다.
- 이런 다양한 경우의 수를 고려해서 연관 매핑과 JPQL/Criteria 쿼리의 로딩 전략을 결정해야 한다.
3) 확장 어려움
- 시스템 초기엔 단일 서버에 단일 DBMS로 서비스를 제공하는 것이 가능하다.
- 문제는 사용자가 몰리기 시작하면서 발생한다.
- 사용자가 늘고 트래픽이 증가하면 자연스럽게 부하를 분산하기 위해 하위 도메인 별로 시스템을 분리하기 시작한다.
- 이 과정에서 하위 도메인마다 서로 다른 DBMS를 사용할 가능성이 높아진다.
- 심지어 하위 도메인마다 다른 종류의 데이터 저장소를 사용하기도 한다. 한 하위 도메인은 마리아DB를 사용하고 다른 하위 도메인은 몽고DB를 사용하는 식으로 말이다.
- 이는 더 이상 다른 애그리거트 루트를 참조하기 위해 JPA와 같은 단일 기술을 사용할 수 없음을 의미한다.
이러한 세 가지 문제를 완화할 때 사용할 수 있는 것이 ID를 이용해서 다른 애그리거트를 참조하는 것이다.
ID를 이용해서 다른 애그리거트를 참조할 경우의 장점
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class ChangeOrderService {
@Transactional
public void changeShippingInfo(OrderId id,
ShippingInfo newShippingInfo,
boolean useNewShippingAddrAsMemberAddr) {
Order order = orderRepository.findbyId(id);
if (order == null) throw new OrderNotFoundException();
order.changeShippingInfo(newShippingInfo);
if (useNewshippingAddrAsMemberAddr) {
// ID를 이용해서 참조하는 애그리거트를 구한다.
Customer customer = customerRepository.findById(order.getOrderer().getCustomerId());
customer.changeAddress(newShippingInfo.getAddress();)
}
}
...
}
|
- 응용 서비스에서 필요한 애그리거트를 로딩하므로 애그리거트 수준에서 지연 로딩을 하는 것과 동일한 결과를 만든다.
- ID를 이용한 참조 방식을 사용하면 복잡도를 낮추는 것과 함께 한 애그리거트에서 다른 애그리거트를 수정하는 문제를 원천적으로 방지할 수 있다.
- 외부 애그리거트를 직접 참조하지 않기에 애초에 한 애그리거트에서 다른 애그리거트의 상태를 변경할 수 없는 것이다.
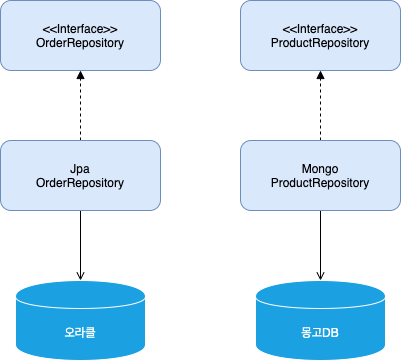
- 애그리거트별로 다른 구현 기술을 사용하는 것도 가능해진다.
- 중요한 데이터인 주문 애그리거트는 RDBMS에 저장하고 조회 성능이 중요한 상품 애그리거트는 NoSQL에 저장할 수 있다.
- 또한, 각 도메인을 별도 프로세스로 서비스하도록 구현할 수도 있다.
[그림3.8] 아이디로 애그리거트를 참조하면 리포지터리마다 다른 저장소를 사용하도록 구현할 떄 확장이 용이하다.
ID를 이용한 참조와 조회 성능
- 다른 애그리거트를 ID로 참조하면 참조하는 여러 애그리거트를 읽어야 할 때 조회 속도가 문제 될 수 있다.
- 예를 들어, 주문 목록을 보여주려면 상품 애그리거트와 회원 애그리거트를 함께 읽어야 하는데, 이를 처리할 때 다음과 같이 각 주문마다 상품과 회원 애그리거트를 읽어온다고 해보자.
- 한 DBMS에 데이터가 있다면 조인을 이용해서 한 번에 가져올 수 있음에도 주문마다 상품 저옵를 읽어오는 쿼리를 실행하게 된다.
1
2
3
4
5
6
7
8
9
| Customer customer = customerRepository.findById(ordererId);
List<Order> orders = orderRepository.findByOrderer(ordererId);
List<OrderView> dtos = orders.stream()
.map(order -> {
ProductId prodId = order.getOrderLines().get(0).getProductId();
// 각 주문마다 첫 번째 주문 상품 정보 로딩 위한 쿼리 실행
Product product = productRepository.findById(prodId);
return new OrderView(order, customer, product);
}).collect(toList());
|
- 위 코드를 보면 Order 조회 쿼리 한 번 그리고 주문에 엮여있는 상품 조회 쿼리 N번이 발생하게 된다.
- 이는 지연 로딩과 관련된 대표적인 문제 N+1 문제와 비슷한 문제가 발생한다.
- N+1 조회 문제는 더 많은 쿼리를 실행해서 전체 조회 속도가 느려지는 원인이다.
- 이 문제가 발생하지 않도록 하려면 조인을 사용하도록 해야하는데 조인을 사용하는 가장 쉬운 방법은 ID 참조 방식을 객체 참조 방식으로 바꾸고 즉시 로딩을 사용하도록 매핑 설정을 바꾸는 것이다.
- 하지만, 이 방식은 애그리거트 간 참조를 ID 참조 방식에서 객체 참조 방식으로 다시 되돌리는 것이다.
- ID 참조 방식을 사용하면서 N+1 조회와 같은 문제가 발생하지 않도록 하려면
전용 조회 쿼리 를 사용하면 된다.- 예를 들어, 데이터 조회를 위한 별도 DAO를 만들고 조회 메서드에서 세타 조인을 이용해서 한 번의 쿼리로 필요한 데이터를 로딩하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| @Repository
public class JpaOrderViewDao implements OrderViewDao {
@PersistenceContext
private EntityManager em;
@Override
public List<OrderView> selectByOrder(String ordererId) {
String selectQuery =
"select new com.myshop.order.application.dto.OrderView(o, m, p) " +
"from Order o join o.orderLines ol, Member m, Product p " +
"where o.orderer.memberId.id = :ordererId " +
"and o.orderer.memberId = m.id " +
"and ol.productId = p.id " +
"order by o.number.number desc";
TypedQuery<OrderView> query =
em.createQuery(selectQuery, OrderView.class);
query.setParameter("ordererId", ordererId);
return query.getResultList();
}
}
|
- 이 JPQL은 Order 애그리거트와 Member 애그리거트, 그리고 Product 애그리거트를 세타 조인으로 조회해서 한 번의 쿼리로 로딩한다.
- 즉시 로딩이나 지연로딩과 같은 로딩 전략을 고민할 필요 없이 조회 화면에서 필요한 애그리거트 데이터를 한 번의 쿼리로 로딩할 수 있다.
- 쿼리가 복잡하거나 SQL에 특화된 기능을 사용해야 한다면 조회를 위한 부분만 MyBatis 와 같은 기술을 이용해서 실행할 수도 있다.
Note: JPA를 사용하면 각 객체 간 모든 연관을 지연/즉시로딩으로 어떻게든 처리하고 싶은 욕구가 생길텐데 이는 실용적이지 않다. ID를 이용해서 애그리거트를 참조해도 한 번의 쿼리로 필요한 데이터를 로딩하는 것이 가능하다.
- 애그리거트마다 서로 다른 저장소를 사용하는 경우엔 한 번의 쿼리로 관련 애그리거트를 조회할 수 없다.
- 이런 경우 조회 성능을 높이기 위해
캐시를 적용하거나 조회 전용 저장소를 따로 구성한다.- 이 방법은 코드가 복잡해지는 단점이 있지만, 시스템의 처리량을 높일 수 있는 장점이 있다.
- 특히 한 대의 DB 장비로 대응할 수 없는 수준의 트래픽이 발생하는 경우
캐시나 조회 전용 저장소는 필수로 선택해야 한다.
애그리거트 간 집합 연관
1:N
- 한 카테고리에 여러 상품이 속할 수 있으니 1:N 관계이다.
1
2
3
4
5
6
7
8
| public class Category {
private Set<Product> products; // 다른 애그리거트에 대한 1:N 연관
//...
public List<Product> getProducts(int page, int size) {
List<Product> sortedProducts = sortById(products);
return sortedProducts.subList((page - 1) * size, page * size);
}
}
|
- 하지만 위처럼 도메인 객체 내에 연관을 맺게 되면 해당 객체가 불릴때마다 Category에 속한 모든 Product를 조회하게 되면서 성능에 심각한 문제를 야기시킨다.
- Product 의 갯수가 수백에서 수만 개정도로 많다면…
- 따라서 개념적으로는 애그리거트 간에 1:N 연관이 있다고 하더라도 성능상 문제로 인해 애그리거트 간의 1:N 연관을 실제 구현에 반영하는 경우는 드물다.
- 이에 대한 해결책으로 상품 입장에서 자신이 속한 카테고리를 N:1 로 연관지어 구하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public class Product {
// ...
private CateogryId category;
//...
}
public class ProductListService {
public Page<Product> getProductOfCategory(Long categoryId, int page, int size) {
Category category = categoryRepository.findById(categoryId);
checkCategory(category);
List<Product> products = productRepository.findByCategoryId(category.getId(), page, size);
int totalCount = productRepository.countByCategoryId(category.getId());
return new Page(page, size, totalCount, products);
}
}
|
- 카테고리에 속한 상품 목록을 제공하는 응용 서비스는 다음과 같이 ProductRepository를 이용해 CategoryId가 지정한 카테고리 식별자인 Product 목록을 구한다.
M:N
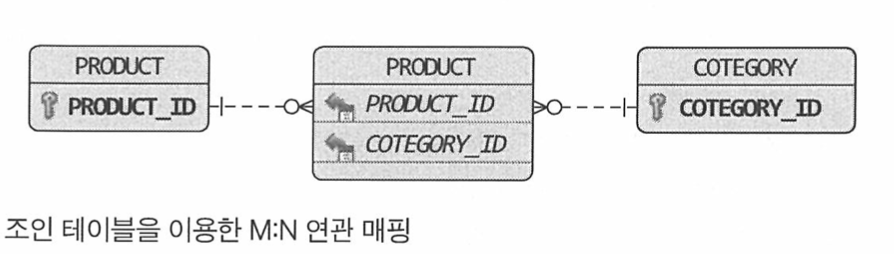
- 상품이 여러 카테고리에 속할 수 있다고 가정하면 카테고리와 상품은 M:N 연관을 맺는다.
- M:N 연관은
개념적으로 양쪽 애그리거트에 컬랙션으로 연관을 만든다.- 하지만 앞선 1:N 처럼 요구사항을 고려해서 M:N 연관을 구현에 포함시킬지 여부를 결정해야 한다.
- 일반적으로 상품 페이지를 보여줄 때 각 상품 별 모든 카테고리 정보를 다 보여주진 않는다.
- 상품 상세 화면에서 주로 카테고리 정보를 보여주게 된다.
- 이 요구사항을 고려하면 카테고리 -> 상품의 연관은 필요하지 않다. 상품 -> 카테고리 연관만 구현하면 된다./b>
- 즉, 개념적으로 상품과 카테고리의 양방향 M:N 연관이 존재하지만 실제 구현에서는 상품 -> 카테고리의 단방향 M:N 연관만 적용하면 된다.
- RDBMS를 이용해 M:N 연관을 구현하려면 조인 테이블을 사용한다.
- JPA 를 이용하면 다음과 같은 매핑 설정을 사용해서 ID 참조를 이용한 M:N 단방향 연관을 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
| @Entity
@Table(name = "product")
public class Product {
@EmbeddedId
private ProductId id;
@ElementCollection
@CollectionTable(name = "product_category",
joinColumns = @JoinColumn(name = "product_id))
private Set<CategoryId> categoryIds;
...
}
|
- 이 매핑은 카테고리 ID 목록을 보관하기 위해 밸류 타입에 대한 컬렉션 매핑을 이용했다.
- 이 매핑을 사용하면 아래 코드와 같이
JPQL의 member of 연산자를 이용해서 특정 Category에 속한 Product 목록을 구하는 기능을 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| @Repository
public class JpaProductRepository implements ProductRepository {
@PersistenceContext
private EntityManager entityManager;
@Override
public List<Product> findByCategoryId(CategoryId categoryid, int page, int size) {
TypedQuery<Product> query = entityManager.createQuery(
"select p from Product p " +
"where :catId member of p.categoryIds order by p.id.id desc", Product.class);
query.setParameter("catId", categoryId);
query.setFirstResult((page - 1) * size);
query.setMaxResults(size);
return query.getResultList();
}
}
|
애그리거트를 팩토리로 사용하기
- 예를 들어, 특정 상점에서 더 이상 상품을 등록을 할 수 없도록 차단된 상태라고 할 때 상품 등록 기능을 아래와 같이 응용 서비스 로직에 구현할 수 있을 것이다. (예제 코드에 오타가 있는 듯하여 임의로 수정했다.)
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class RegisterProductService {
public ProductId registerNewProduct(NewProductRequest req) {
Store store = accountRepository.findStoreById(req.getStoreId());
checkNull(store);
if (store.isBlocked()) {
throw new StoreBlockedException();
}
ProductId id = productRepository.nextId();
Product product = accout.createProduct(id, store.getId(), ...);
productRepository.save(product);
return id;
}
}
|
- 코드가 나빠조이진 않지만 중요한 도메인 로직 처리가 응용 서비스에 노출되었다.
- Store가 Product 를 생성할 수 있는지 여부를 판단하고 Product를 생성하는 것은 논리적으로 하나의 도메인 기능인데 이 도메인 기능을 응용 서비스에서 구현하고 있는 것이다.
- 이 도메인 기능을 넣기 위한 별도의 도메인서비스나 팩토리 클래스를 만들수도 있지만 이 기능을 구현하기에 더 좋은 장소는 Store 애그리거트이다.
- Product를 생성하는 기능을 Store 애그리거트에 다음과 같이 옮겨보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class Store extends Member {
public Product createProduct(ProductId newProductId, /*...*/) {
if (isBlocked()) throw new StoreBlockedException();
return new Product(newProductId, getId(), /*...*/);
}
}
public class RegisterProductService {
public ProductId registerNewProduct(NewProductRequest req) {
Store account = accountRepository.findStoreById(req.getStoreId());
checkNull(account);
ProductId id = productRepository.nextId();
Product product = accout.createProduct(id, /*...*/);
productRepository.save(product);
return id;
}
}
|
- Store 애그리거트의 createProduct() 는 Product 애그리거트를 생성하는 패고틸 역할을 한다.
- 앞선 코드와 차이점이라면 응용 서비스에서 더 이상 Store의 상태를 확인하지 않는 다는 것이다.
- 이렇게 함으로써 도메인 응집도도 높아지게 된다.
밸류 컬렉션을 @Entity로 매핑하기
Reference