
본 포스팅은 인프러의 JPA 기본편을 수강하고 정리하는 내용입니다.
대부분의 기업들은 객체 지향 언어(java, scala)를 사용한다. 또한 DB로는 관계형 DB를 많이 사용하고 있다. 그래서 지금 시대는 객체를 관계형 DB에 관리하는 시대이다.
문제는 애플리케이션은 객체 지향 개발하면서 하는데 딱 코드를 까보면 SQL만 천지이다.
결국엔 SQL 중심적인 개발이 되게 많은 문제점을 야기한다.
1. 무한 반복, 지루한 코드
- CRUD 쿼리 무한 반복해야됨, 테이블이 10개면 10개를 다해줘야해서 생산성이 저하되고 힘듬(객체에 필드가 추가되면 쿼리들에 하나씩 일일이 다 추가해줘야함)
2. 패러다임의 불일치(객체 지향 vs 관계형 데이터베이스)
- 관계형 DB는 데이터를 정교화해서 저장하는게 목표이고, 객체는 필드나 메서드 같은게 묶여서 캡슐화해서 쓰는게 목표이다.
- 이처럼 이 둘의 패러다임이 안맞기에 여러 가지 문제가 생기게 된다.
- RDB가 인식할 수 있는 것은 SQL뿐이기 때문에 결국, Object를 SQL로 짜야한다.
- 객체 ->
SQL 변환-> RDB에 저장 개발자 == SQL 매퍼라고 할만큼 SQL 작업을 너무 많이 하고 있다.
- 객체 ->
3. 객체와 관계형 데이터베이스의 차이
1) 상속
객체에는 상속 관계가 있지만, 관계형 DB에는 상속 관계가 없다. (유사한게 있긴 함)
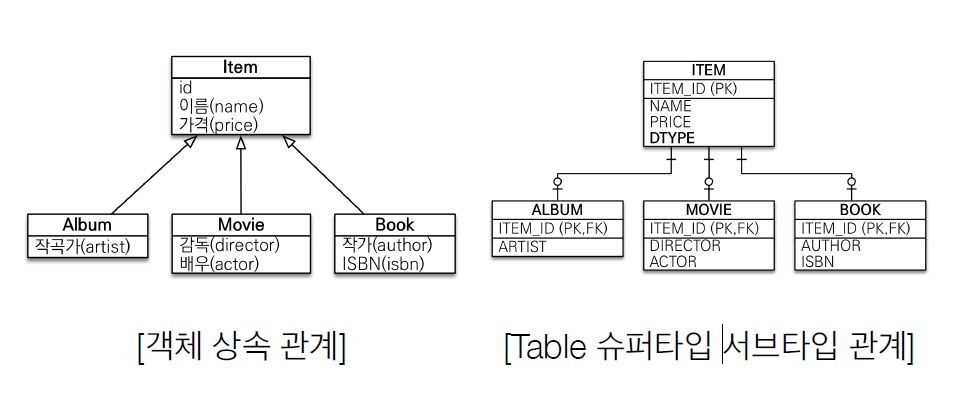
객체의 상속 관계와 유사한 모델이 RDB의 슈퍼타입 서브타입 관계이다. Album을 DB에 저장한다하면 ITEM테이블 삽입 sql, ALBUM테이블 삽입 sql 총 2개를 작성해야 한다. 만약 Album을 조회한다하면 조인으로 Album 테이블과 ITEM테이블을 조회해서 나온 결과 값을 일일이 Album 객체와 Item 객체에 일일이 필드 값을 넣어줘야 한다. 이러한 문제로 개발자는 SQL 매핑 작업을 한땀 한땀 하다보면 생산성이 저하되게 되며 실수할 가능성도 높아지게 된다.
자바 컬렉션에 저장한다면?
조회시 단순하게
1
list.add(album);
자바 컬렉션에 조회한다면?
1
Album album = list.get(albumId);
부모 타입으로 조회 후 다형성 활용
1
Item item = list.get(albumId);
2) 연관관계
객체는 레퍼런스를 가질 수 있지만, RDB는 PK, FK를 사용하여 join을 사용해야한다.
- 객체는
참조를 사용: member.getTeam() - 테이블은
외래 키를 사용: JOIN ON M.TEAM_ID = T.TEAM_ID
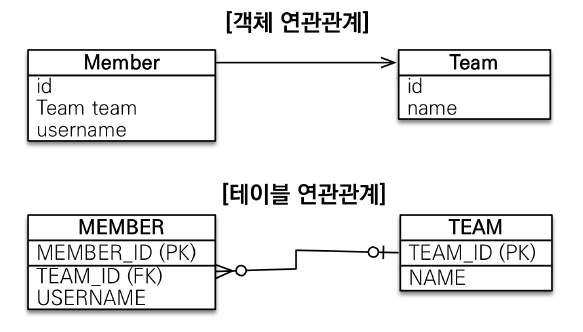
- Object
- 참조(Reference)를 사용하여 연관 관계를 찾는다.
(Member.getTeam()) - 양뱡향 참조 할 수 없다. (Member에서 Team으로 참조가능하지만, Team에서 Member로는 불가능하다)
- 참조(Reference)를 사용하여 연관 관계를 찾는다.
- RDB
- 외래키(FK)를 사용하여 Join 쿼리를 통해 연관 관계를 찾는다.
(JOIN ON M.TEAM_ID = T.TEAM_ID) - 양방향 참조 가능하다.(테이블은 Team에서 Member로도 fk로 join을 통해 참조가능하다)
- 외래키(FK)를 사용하여 Join 쿼리를 통해 연관 관계를 찾는다.
3) 데이터 타입
4) 데이터 식별 방법
4. 모델링 과정에서의 문제
객체를 테이블에 맞추어 모델링
1
2
3
4
5
6
7
8
9
class Member {
String id; // MEMBER_ID 컬럼 사용
Long teamId; // TEAM_ID FK 컬럼 사용 //**
String username; // USERNAME 컬럼 사용
}
class Team {
Long id; // TEAM_ID PK 사용
String name; // NAME 컬럼 사용
}
MEMBER.TEAM_ID에 해당하는 FK를 그대로 필드에 추가한다.(Long teamId) 이렇게 설계된 객체를 DB에 저장 하려면 아래와 같이 쿼리를 작성해야한다.
1
INSERT INTO MEMBER(MEMBER_ID, TEAM_ID, USERNAME) VALUES ...
하지만 이는 객체지향스럽지 않다는 문제가 존재한다. Team 객체의 참조값 자체가 필드에 들어가는 것이 더 객체지향스럽다고 할 수 있다.
객체지향스러운 모델링
1
2
3
4
5
6
7
8
9
10
11
12
13
class Member {
String id; // MEMBER_ID 컬럼 사용
Team team; // 참조로 연관관계를 맺는다. //**
String username; // USERNAME 컬럼 사용
Team getTeam() {
return team;
}
}
class Team {
Long id; // TEAM_ID PK 사용
String name; // NAME 컬럼 사용
}
Team 객체의 참조값 자체를 필드에 넣는다.(Team team;) 이렇게 설계된 객체를 DB에 저장하려면 아래의 insert 쿼리를 작성해야 한다.
1
INSERT INTO MEMBER(MEMBER_ID, TEAM_ID, USERNAME) VALUES ...
여기서 TEAM_ID를 얻으려면 member.getTeam().getId()로 값을 얻어와야 한다. 하지만 이렇게 객체지향적으로 설계하면 조회할 때 문제가 생긴다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
public Member find(String memberId) {
//SQL 실행 ...
Member member = new Member();
//데이터베이스에서 조회한 회원 관련 정보를 모두 입력
Team team = new Team();
//데이터베이스에서 조회한 팀 관련 정보를 모두 입력
//회원과 팀 관계 설정
member.setTeam(team); //**
return member;
}
Member랑 Team을 조인하여 조회한 다음에 값을 일일이 설정해주고나서 반환해 줘야한다. 이러한 과정들은 너무 번거롭다. 만약 자바 컬렉션에서 관리한다면 과정들이 단순해진다.
객체 모델링, 자바 컬렉션에 관리
1
2
3
list.add(member);
Member member = list.get(memberId);
Team team = member.getTeam();
- 단순하게 list에 add로 저장하고, get으로 조회하고 코드 한줄로 해결가능하다.
5. 객체 그래프 탐색
객체는 자유롭게 객체 그래프를 탐색 할 수 있어야 한다.
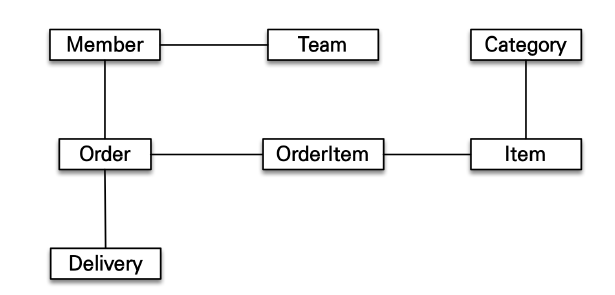
하지만 여기서 문제는 처음 실행하는 SQL에 따라 탐색 범위가 결정되는 문제가 발생한다. 예를 들어, 아래 조회 쿼리를 작성 후 getTeam() 메서드를 통해 Team객체를 조회하는 것은 가능하지만 Order 객체를 조회하는 것은 불가능하다. (처음 SQL 실행 할 때 Member랑 Team만 조회해서 가져오기 때문에)
1
2
3
4
5
6
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
member.getTeam(); //OK
member.getOrder(); //null
위와 같은 문제는 엔티티 신뢰 문제 를 야기한다.
엔티티 신뢰 문제
1
2
3
4
5
6
7
8
class MemberService {
...
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam(); //???
member.getOrder().getDelivery(); // ???
}
}
memberDAO에서 어떤 쿼리를 날렸는지 알 수 없는 이상 자유롭게 getTeam(), getOrder()와 같은 메서드를 사용할 수 없다. 즉 신뢰성이 떨어진다.
그렇다고 해서 모든 객체를 미리 로딩할 수도 없다. 상황에 따라 동일한 회원 조회 메서드를 여러벌 생성해야한다.
1
2
3
memberDAO.getMember(); //Member만 조회
memberDAO.getMemberWithTeam();//Member와 Team 조회
memberDAO.getMemberWithOrderWithDelivery(); // //Member, Order, Delivery 전부 조회
이렇게 SQL을 직접 다루면 계층형 아키텍처(Layered 아키텍처)에서 진정한 의미의 계층 분할이 어렵다. 물리적으로는 계층이 나누어져 있지만, 논리적으로는 굉장히 강결합되어 있다.
6. 비교하기에서의 차이
1
2
3
4
String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
member1 == member2; //다르다.
식별자가 똑같아도 getMember를 통해 조회한 두 member1과 member2는 다르다. 왜냐하면 아래 MemberDAO클래스의 getMember() 메소드에서 매번 new로 객체를 생성하기 때문이다.
1
2
3
4
5
6
7
8
class MemberDAO {
public Member getMember(String memberId) {
String sql = "SELECT * FROM MEMBER WHERE MEMBER_ID = ?";
...
//JDBC API, SQL 실행
return new Member(...);
}
}
만약 자바 컬렉션에서 조회 한다고 해보자.
1
2
3
4
String memberId = "100";
Member member1 = list.get(memberId);
Member member2 = list.get(memberId);
member1 == member2; //같다.
식별자가 같을 때 컬렉션에서의 두 객체의 참조값은 같기 때문에 두 객체는 같다.
정리
객체답게 모델링 할 수록 매핑 작업만 늘어나고 더 힘들어진다. 내가 객체지향적인 것을 배우고 이처럼 설계할 수록 훨씬 번잡해지게 된다.
그래서 객체를 자바 컬렉션에 저장 하듯이 DB에 저장하고 불러올 수 있는 방법이 없을까를 고민해왔고 그 고민의 결과가 JPA 이다.