Chapter5-형식 맞추기
프로그래머라면 형식을 깔끔하게 맞춰 코드를 짜야 한다. 코드 형식을 맞추기 위한 간단한 규칙을 정하고 그 규칙을 착실히 따라야 한다. 팀으로 일한다면 팀이 합의해 규칙을 정하고 모두가 그 규칙을 따라야 한다. 필요하다면 규칙을 자동으로 적용하는 도구를 활용한다. (ex. intellij의 codestyle이 이러한 도구 중 하나가 될 것 같다)
형식을 맞추는 목적
- 코드 형식은 중요하다!
- 오늘 구현한 기능이 다음 버전에서 ㅂ바뀔 확률은 아주 높다.
- 그런데 오늘 구현한 코드의 가독성은 앞으로 바뀔 코드 품질에 지대한 영향을 미친다.
- 오랜 시간이 지나 원래 코드의 흔적을 더 이상 찾아보기 어려울 정도로 코드가 바뀌어도 맨 처음 잡아높은 구현 스타일과 가독성 수준은 유지보수 숑이성과 확장성에 계속 영향을 미친다.
- 원래 코드는 사라질지라도 개발자의 스타일과 규율은 사라지지 않는다.
- 그렇다면 원활한 소통을 장려하는 코드 형식은 무엇일까?
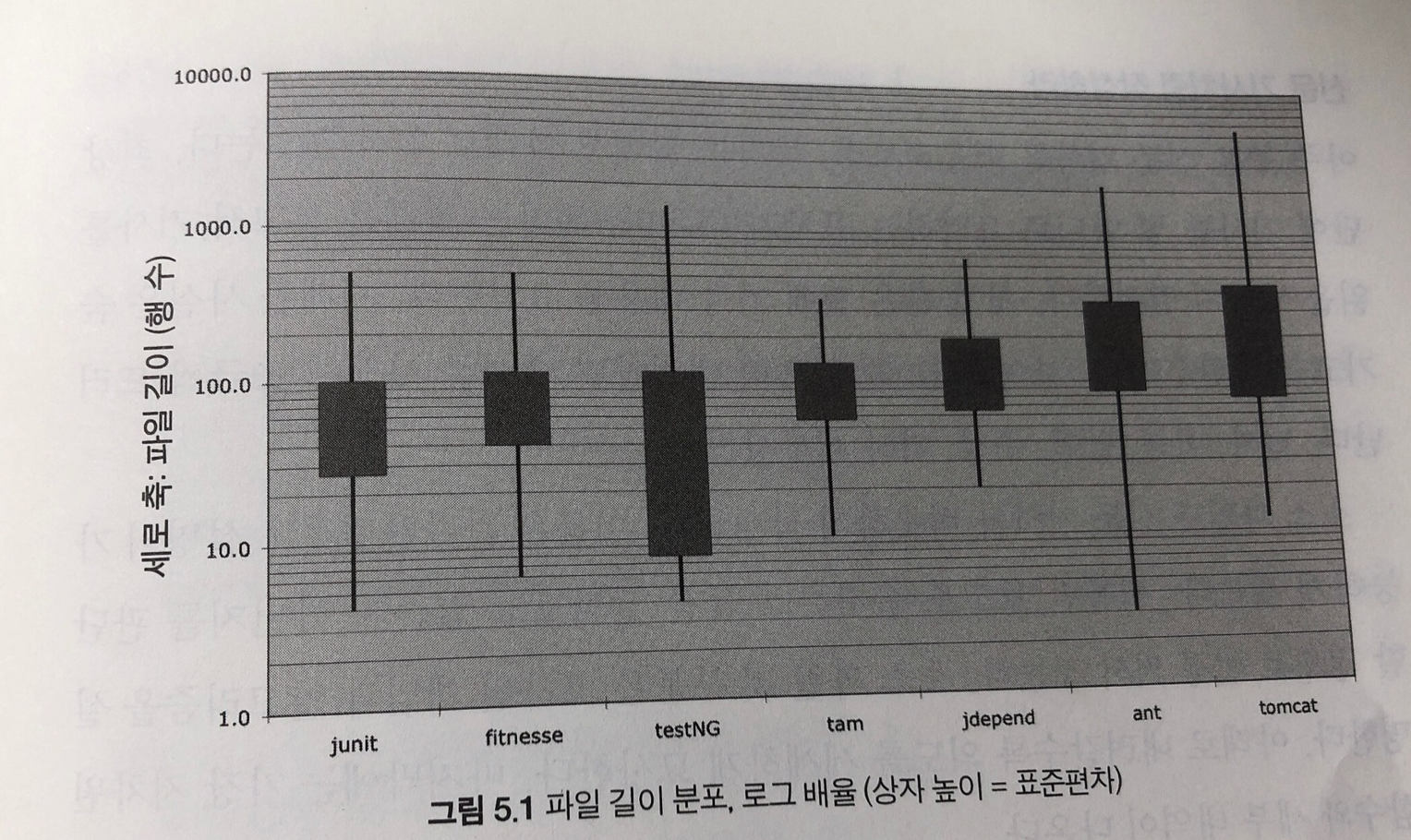
적절한 행길이를 유지하라

- 표5-1 이 우리에게 말하는 바는 다음과 같다.
- 500줄을 넘지 않고 대부분 200줄 정도인 파일로도 커다란 시스템을 구축할 수 있다는 사실이다.
- 반드시 지킬 엄격한 규칙은 아니지만 바람직한 규칙으로 삼으면 좋겠다.
- 일반적으로 큰 파일보단 작은 파일이 이해하기 쉽다.
신문 기사처럼 작성하라
- 독자는 위에서 아래로 기사를 읽는다.
- 최상단에 기사를 몇 마디로 요약하는 표제가 나온다.
- 독자는 표제를 보고서 기사를 읽을지 말지를 결정한다.
- 첫 문단은 전체 기사 내용을 요약한다.
- 세세한 사실은 숨기고 커다란 그림을 보여준다.
- 쭉 읽으며 내려가면 세세한 사실이 조금씩 드러난다.
- 날짜, 이름, 발언, 주장, 기타 세부사항이 나온다.
- 소스 파일도 위의 신문 기사와 비슷하게 작성한다.
- 이름은 간단하면서도 설명이 가능하게 짓는다.
- 이름만 보고도 올바른 모듈을 살펴보고 있는지 아닌지를 판단할 정도로 신경써서 짓는다.
- 소스 파일 첫 부분은 고차원 개념과 알고리즘을 설명한다.
- 아래로 내려갈수록 의도를 세세하게 묘사한다.
- 마지막에는 가장 저차원 함수와 세부 내역이 나온다.
- 신문은 다양한 기사로 이뤄진다.
- 대다수 기사가 아주 짧다.
- 어떤 기사는 조금 길다. 한 면을 채우는 기사는 거의 없다.
- 신문이 읽을 만한 이유는 여기에 있다.
- 신문이 사실, 날짜, 이름 등을 무작위로 뒤섞은 긴 기사 하나만 싣는다면 아무도 읽지 않으리라.
개념은 빈행으로 분리하라.
- 각 행은 수식이나 절을 나타내고, 일련의 행 묶음은 완결된 생각 하나를 표현한다. 생각 사이는 빈 행을 넣어 분리해야 마땅하다.
- 패키지 선언부, import문, 각 함수 사이에는 빈행이 들어간다.
- 빈 행은 새로운 개념을 시작한다는 시각적 단서다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| package fitnesse.wikitext.widgets;
import java.util.regex.*;
public class BoldWidget extends ParentWidget {
public static final String REGEXP = "'''.+?'''";
private static final Pattern pattern = Pattern.compile("'''(.+?)'''", Pattern.MULTILINE + Pattern.DOTALL);
public BoldWidget(ParentWidget parent, String text) throws Exception {
super(parent);
Matcher match = pattern.matcher(text);
match.find();
addChildWidgets(match.group(1));
}
public String render() throws Exception {
StringBuffer html = new StringBuffer("<b>");
html.append(childHtml()).append("</b>");
return html.toString();
}
}
|
- 만약 위의 코드에서 빈 행을 빼뜨리면 아래와 같아질 것인데, 코드 가독성이 현재하게 떨어지게 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| package fitnesse.wikitext.widgets;
import java.util.regex.*;
public class BoldWidget extends ParentWidget {
public static final String REGEXP = "'''.+?'''";
private static final Pattern pattern = Pattern.compile("'''(.+?)'''", Pattern.MULTILINE + Pattern.DOTALL);
public BoldWidget(ParentWidget parent, String text) throws Exception {
super(parent);
Matcher match = pattern.matcher(text);
match.find();
addChildWidgets(match.group(1));
}
public String render() throws Exception {
StringBuffer html = new StringBuffer("<b>");
html.append(childHtml()).append("</b>");
return html.toString();
}
}
|
세로 밀집도
- 세로 밀집도는 연관성을 의미한다.
- 즉, 서로 밀집한 코드 행은 세로로 가까이 놓아야 한다는 뜻이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| //안 좋은 예시 - 의미없는 주석과 공백은 코드를 다른 개념으로 인식시킨다.
public class ReporterConfig {
/*
* 리포터 리스너의 클래스 이름
*/
private String m_className;
/*
* 리포터 리스너의 속성
*/
private List<Property> m_properties = new ArrayList<Property>();
public void addProperty(Property property) {
m_properties.add(property);
}
}
//개선 - 공백을 제거하여 같은 개념임을 표현할 수 있다. (코드가 훨씬 눈에 잘 들어온다)
public class ReporterConfig {
private String m_className;
private List<Property> m_properties = new ArrayList<Property>();
public void addProperty(Property property) {
m_properties.add(property);
}
}
|
수직 거리
- 서로 밀집한 개념은 세로로 가까이 둬야 한다.
- 물론 두 개념이 서로 다른 파일에 속한다면 규칙이 통하지 않는다.
- 하지만 타당한 근거가 없다면 서로 밀집한 개념은 한 파일이 속해야 마땅하다.
- 이게 바로
protected 변수를 피해야 하는 이유 중 하나다.
변수 선언
- 변수는 사용하는 위치에 최대한 가까이 선언한다.
- 우리가 만든 함수는 매우 짧으므로 지역 변수는 각 함수 맨 처음에 선언한다.
인스턴스 변수
- 인스턴스 변수는 클래스 맨 처음에 선언한다.
- 변수 간에 세로로 거리를 두지 않는다.
- 잘 설계한 클래스는 많은 (혹은 대다수) 클래스 메서드가 인스턴스 변수를 사용하기 때문이다.
- 인스턴스 변수를 선언하는 위치는 아직도 논쟁이 분분하다.
- 일반적으로 C++ 은 클래스 마지막에 선언하고, 자바는 맨 처음에 선언한다.
- 하지만 이 논쟁보단 잘 알려진 위치에 인스턴스 변수를 모은다는 사실이 중요하다. 변수 선언을 어디서 찾을지 모두가 알고 있어야 한다.
종속 함수
- 한 함수가 다른 함수를 호출한다면 두 함수는 세로로 가까이 배치한다.
- 또한, 가능하다면 호출하는 함수를 호출되는 함수보다 먼저 배치한다. 그러면 프로그램이 자연스럽게 읽히게 될 것이다.
- 규칙을 일관적으로 적용한다면 독자는 방금 호출한 함수가 잠시 후에 정의되리라는 사실을 예측할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| // 목록5-5
public class WikiPageResponder implements SecureResponder {
protected WikiPage page;
protected PageData pageData;
protected String pageTitle;
protected Request request;
protected PageCrawler crawler;
public Response makeResponse(FitNesseContext context, Request request) throws Exception {
String pageName = getPageNameOrDefault(request, "FrontPage");
loadPage(pageName, context);
if (page == null) {
return notFoundResponse(context, request);
} else {
return makePageResponse(context);
}
}
private String getPageNameOrDefault(Request request, String defaultPageName) {
String pageName = request.getResource();
if (StringUtil.isBlank(pageName)) {
pageName = defaultPageName;
}
return pageName;
}
protected void loadPage(String resource, FitNesseContext context) throws Exception {
WikiPagePath path = PathParser.parse(resource);
crawler = context.root.getPageCrawler();
crawler.setDeadEndStrategy(new VirtualEnabledPageCrawler());
page = crawler.getPage(context.root, path);
if (page != null) {
pageData = page.getData();
}
}
private Response notFoundResponse(FitNesseContext context, Request request) throws Exception {
return new NotFoundResponder().makeResponse(context, request);
}
private SimpleResponse makePageResponse(FitNesseContext context) throws Exception {
pageTitle = PathParser.render(crawler.getFullPath(page));
String html = makeHtml(context);
SimpleResponse response = new SimpleResponse();
response.setMaxAge(0);
response.setContent(html);
return response;
}
}
...
|
- 위 코드의
getPagenameOrDefault 함수 안에서 "FrontPage" 상수를 사용하는 방법도 있다.- 하지만 그러면 기대와는 달리 잘 알려진 상수가 적절하지 않은 저차원 함수에 묻힌다.
- 상수를 알아야 마땅한 함수에서 실제로 사용하는 함수로 상수를 넘겨주는 방법이 더 좋다.
개념 유사성
- 친화도가 높을수록 코드를 가까이 배치한다.
- 친화도가 높은 요인은 여러가지다.
- 한 함수가 다른 함수를 호출해 생기는 직접적인 종속성이 한 예다.
- 변수와 그 변수를 사용하는 함수도 한 예다.
- 비슷한 동작을 수행하는 일군의 함수도 좋은 예다.
세로 순서
- 호출되는 함수를 호출하는 함수보다 나중에 배치한다.
- 그러면 소스 코드 모듈이 고차원에서 저차원으로 자연스럽게 내려간다.
- 그러면 마치 신문처럼 읽히게 될 것이다.
- 세세한 사항은 가장 마지막에 표현하게 될텐데 그러면 독자가 소스 파일에서 첫 함수 몇 개만 읽어도 개념을 파악하기 쉬워진다.
- 코드를 처음 접한 사람 또는 유지보수할 때 굳이 세세한 사항까지 매번 파고들 필요가 없어지고 가독성도 좋아지게 될 것이다.
목록5-5가 좋은 예다.
가로 형식 맞추기
- 가로길이는 20자~60자 사이인 행이 총 행수의 40%에 달한다는 말이다.
- 10자 미만은 30%정도로 보인다.
- 프로그래머는 짧은 행을 선호한다.
- 100자나 120자에 달해도 나쁘지 않다. 하지만 그 이상은 솔직히 주의부족이다.
- 예전보다 큰 모니터들을 많이 사용해서 한 화면에 200자까지도 들어가지만 가급적으론 120자 정도로 행 길이를 제한하자.
가로 공백과 밀집도
1
2
3
4
5
6
7
| private void measureLine(String line) {
lineCount++;
int lineSize += line.length();
totalCHars += lineSize;
lineWithHistogram.addLine(lineSize, lineCount);
recordWidestLine(lineSize);
}
|
- 할당 연산자를 강조하기 위해 앞뒤에 공백을 주었다.
- 하지만 함수 이름과 이어지는 괄호 사이에는 공백이 없다.
- 함수와 인수는 인접하기 때문이다.
- 공백을 넣게되면 한 개념이 아니라 별개로 보이게 된다.
- 함수를 호출하는 코드에서 괄호 안 인수는 공백으로 분리했다.
- 쉼표를 강조해 인수가 별개라는 사실을 보여주기 위해서다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class Quadratic {
public static double root1(double a, double b, double c) {
double determinant = determinant(a, b, c);
return (-b + Math.sqrt(determinant) / (2*a));
}
public static double root2(double a, double b, double c) {
double determinant = determinant(a, b, c);
return (-b - Math.sqrt(determinant) / (2*a));
}
private static double determinant(double a, double b, double c) {
return b*b - 4*a*c;
}
}
|
- 연산자 우선순위를 강조하기 위해서도 공백을 사용한다.
- 승수 사이는 공백이 없다.
- 항 사이에는 공백기 들어간다.
- 덧셈과 뺼셈은 우선순위가 곱셈보다 낮기 때문이다.
- 불행히도 코드 형식을 자동으로 맞춰주는 도구는 대다수가 연산자 우선순위를 고려하지 못하므로, 수식에 똑같은 간격을 적용한다.
- 따라서 위와 같이 공백을 넣어줘도 나중에 도구에서 없애는 경우가 흔하다.
가로 정렬
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public class FitNesseExpediter implements ResponseSender
{
private Socket socket;
private InputStream input;
private OutputStream output;
private Request request;
private Response response;
private FitnesseContext context;
private long requestParsingTimeLimit;
private long requestProgress;
private long requestParsingDeadline;
private boolean hasError;
public FitNessExpediter(Socket s,
FitNesseContext context) throws Exception
{
this.context = context;
socket = s;
input = s.getInputStream();
output = s.getOutputStream();
requestParsingTimeLinit = 10000;
}
}
|
- 위와 같은 정렬은 유용하지 않다.
- 코드가 엉뚱한 부분을 강조해 진짜 의도가 가려지기 때문이다.
- 예를 들어, 위 선언부를 읽다 보면 변수 유형은 무시하고 변수 이름부터 읽게 된다.
- 마찬가지로, 위 할당문을 훑어보면 할당 연산자는 보이지 않고 오른쪽 피연산자에 눈이 간다.
- 설상가상으로 코드 형식을 자동으로 맞춰주는 도구는 대다수가 위와 같은 정렬을 무시한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class FitNesseExpediter implements ResponseSender
{
private Socket socket;
private InputStream input;
private OutputStream output;
private Request request;
private Response response;
private FitnesseContext context;
private long requestParsingTimeLimit;
private long requestProgress;
private long requestParsingDeadline;
private boolean hasError;
public FitNessExpediter(Socket s, FitNesseContext context) throws Exception
{
this.context = context;
socket = s;
input = s.getInputStream();
output = s.getOutputStream();
requestParsingTimeLinit = 10000;
}
}
|
- 위와 같이 정렬하지 않게되면 오히려 중대한 결함을 찾기 쉬워진다.
- 정렬이 필요할 정도로 목록이 길다면 문제는 길이지 정렬 부족이 아니다.
들여쓰기
1
2
3
4
5
6
7
8
| public class Product {
private String name;
public String getName() {
return this.name;
}
}
|
- 들여쓰기한 파일은 구조가 한눈에 들어온다.
- 변수, 생성자 함수, 접근자 함수, 메서드가 금방 보인다.
- 반면, 들여쓰기 하지 않은 코드는 열심히 분석하지 않는 한 거의 불가해하다.
들여쓰기 무시하기
- 간단한 if문, 짧은 while문, 짧은 함수에서도 들여쓰기로 범위를 제대로 표현한 코드가 좋다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // bad
public class CommentWidget extends TextWidget {
public static final String REGEXP = "^#[^\r\n]*(?:(?:\r\n)|\n|\r)?";
public CommentWidget(ParentWidget parent, String text){super(parent, text);}
public String render() throws Exception {return ""; }
}
// good
public class CommentWidget extends TextWidget {
public static final String REGEXP = "^#[^\r\n]*(?:(?:\r\n)|\n|\r)?";
public CommentWidget(ParentWidget parent, String text){
super(parent, text);
}
public String render() throws Exception {
return "";
}
}
|
가짜 범위
- 빈 while문이나 for문은 가능한 피해라.
- 피하지 못할땐 빈 블록을 올바로 들여쓰고 괄호로 감싼다.
- 세미콜론(;)은 새행에다 제대로 들여써서 넣어준다.
팀 규칙
- 팀에 속한다면 자신이 팀의 규칙을 따르는 것이 무엇보다 중요하다.
- 그래야 소프트웨어가 일관적인 스타일을 보인다.
- 개개인이 따로국밥처럼 맘대로 짜대는 코드는 피해야 한다.
- 좋은 소프트웨어 시스템은 읽기 쉬운 문서로 이뤄진다는 사실을 기억하기 바란다.
- 스타일은 일관적이고 매끄러워야 한다.
- 한 소스 파일에서 봤던 형식이 다른 소스 파일에도 쓰이리라는 신뢰감을 독자에게 줘야 한다.
- 온갖 스타일을 뒤섞어 소스 코드를 필요 이상으로 복잡하게 만드는 실수는 반드시 피한다.
밥 아저씨의 코드 규칙
- 밥 아저씨의 코드 규칙은 아래 코드를 통해 확인할 수 있다.
- 코드 자체가 최고의 구현 표준 문서가 되는 예다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| // 목록5-6
public class CodeAnalyzer implements JavaFileAnalysis {
private int lineCount;
private int maxLineWidth;
private int widestLineNumber;
private LineWidthHistogram lineWidthHistogram;
private int totalChars;
public CodeAnalyzer() {
lineWidthHistogram = new LineWidthHistogram();
}
public static List<File> findJavaFiles(File parentDirectory) {
List<File> files = new ArrayList<File>();
findJavaFiles(parentDirectory, files);
return files;
}
private static void findJavaFiles(File parentDirectory, List<File> files) {
for (File file : parentDirectory.listFiles()) {
if (file.getName().endsWith(".java"))
files.add(file);
else if (file.isDirectory())
findJavaFiles(file, files);
}
}
public void analyzeFile(File javaFile) throws Exception {
BufferedReader br = new BufferedReader(new FileReader(javaFile));
String line;
while ((line = br.readLine()) != null)
measureLine(line);
}
private void measureLine(String line) {
lineCount++;
int lineSize = line.length();
totalChars += lineSize;
lineWidthHistogram.addLine(lineSize, lineCount);
recordWidestLine(lineSize);
}
private void recordWidestLine(int lineSize) {
if (lineSize > maxLineWidth) {
maxLineWidth = lineSize;
widestLineNumber = lineCount;
}
}
public int getLineCount() {
return lineCount;
}
public int getMaxLineWidth() {
return maxLineWidth;
}
public int getWidestLineNumber() {
return widestLineNumber;
}
public LineWidthHistogram getLineWidthHistogram() {
return lineWidthHistogram;
}
public double getMeanLineWidth() {
return (double)totalChars/lineCount;
}
public int getMedianLineWidth() {
Integer[] sortedWidths = getSortedWidths();
int cumulativeLineCount = 0;
for (int width : sortedWidths) {
cumulativeLineCount += lineCountForWidth(width);
if (cumulativeLineCount > lineCount/2)
return width;
}
throw new Error("Cannot get here");
}
private int lineCountForWidth(int width) {
return lineWidthHistogram.getLinesforWidth(width).size();
}
private Integer[] getSortedWidths() {
Set<Integer> widths = lineWidthHistogram.getWidths();
Integer[] sortedWidths = (widths.toArray(new Integer[0]));
Arrays.sort(sortedWidths);
return sortedWidths;
}
}
|
예제 코드 출처
Chapter6-객체와 자료 구조
자료 추상화
- 구현을 감추려면 추상화가 필요하다.
- 그저 조회 함수와 설정 함수로 변수를 다룬다고 클래스가 되진 않는다.
- 그보다는 추상 인터페이스를 제공해 사용자가 구현을 모른 채 자료의 핵심을 조작할 수 있어야 진정한 의미의 클래스다.
1
2
3
4
5
6
7
8
9
| //구체적인 Vehicle 클래스
public interface Vehicle {
double getFuelTankCapacityInGallons(); //get 함수를 사용하지만 어떤 변수 값을 반환할 뿐이라는 점은 쉽게 드러난다. (실제 클래스의 필드)
double getGallonsOfGasoline();
}
//추상적인 Vehicle 클래스
public interface Vehicle {
double getPercentFuelRemainint(); //추상적인 개념을 사용하여 내용을 숨길 수 있다.
}
|
- 자료를 세세하게 공개하기보단 추상적인 개념으로 표현하는 편이 좋다.
- 인터페이스나 조회/설정 함수만으로는 추상화가 이뤄지지 않는다.
- 아무 생각 없이 무분별하게 getter, setter를 만들지 말자.
자료/객체 비대칭
- 객체는 추상화 뒤로 자료를 숨긴 채 자료를 다루는 함수만 공개한다.
- 객체 지향 코드는 기존 함수를 변경하지 않으면서 새 클래스를 추가하기 쉽다.
- 즉, Shape 인터페이스를 구현한 클래스만 추가해주면 된다.
- 반면 새로운 함수를 추가하려면 모든 클래스를 수정해야 한다.
- 즉, 모든 Shape 구현 클래스에 해당 함수를 구현해줘야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| public class Square implements Shape {
private Point topLeft;
private double side;
public double area() {
return side * side;
}
}
public class Rectangle implements Shape {
private Point topLeft;
private double height;
private double width;
public double area() {
return height * width;
}
}
public class Circle implements Shape {
private Point center;
private double radius;
public final double PI = 3.14159265;
public double area() {
return PI * radius * radius;
}
}
|
- 자료 구조는 자료를 그대로 공개하며 별다른 함수는 제공하지 않는다.
- 절차적인 코드는 기존 자료 구조를 변경하지 않으면서 새 함수를 추가하기 쉽다.
- 반면 새로운 자료구조를 추가하기 어렵다. 자료구조를 사용하는 모든 함수를 수정해야 한다.
- area 함수처럼 해당 자료구조를 사용하는 모든 함수를 수정해줘야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| public class Square {
public Point topLeft;
public double side;
}
public class Rectangle {
public Point topLeft;
public double height;
}
public class Circle {
public Point center;
public double radius;
}
public class Geometry {
public final double PI = 3.14159265;
public double area(Object shape) throws NoSuchShapeException{
if (shape instanceof Square) {
Square s = (Square)shape;
return s.side * s.side;
}
else if (shape instanceof Rectangle) {
Rectangle r = (Rectangle)shape;
return r.height * r.width;
}
else if (shape instanceof Circle) {
Circle c = (Circle)shape;
return PI * c.radius * c.radius;
}
throw new NoSuchShapeException();
}
}
|
- 위의 내용을 살펴보면 객체와 자료구조는 본질적으로 상반된다.
Note: 복잡한 시스템을 개발하다 보면 새로운 함수가 아닌 새로운 자료 타입이 필요한 경우가 생긴다. 이때는 클래스와 객체 지향 기법이 가장 적합하다. 반면, 새로운 자료 타입이 아닌 새로운 함수가 필요한 경우도 있다. 이땐 절차적인 코드와 자료 구조가 좀 더 적합하다.
- 이처럼 둘의 장단점을 고려하여 객체와 자료구조를 적절하게 사용하는게 좋다.
디미터 법칙
- 모듈은 자신이 조작하는 객체의 속사정을 몰라야 한다는 법칙이다.
- 즉, 객체는 조회 함수로 내부 구조를 공개하면 안된다는 의미다.
- 그러면 내부 구조를 (숨기지 않고) 노출하는 셈이니까..
- 클래스 C의 메서드 f는 다음과 같은 객체의 메서드만 호출해야 한다.
- 클래스 C
- f 가 생성한 객체
- f 인수로 넘어온 객체
- C 인스턴스 변수에 저장된 객체
기차 충돌
- 객체에서 허용된 메서드가 반환하는 객체의 메서드는 호출하면 안 된다.
- 여러 객체가 한 줄로 이어진 기차처럼 보이는 코드를 기차 충돌(train wreck)이라 한다.
- 일반적으로 조잡하다 여겨지는 방식이므로 피하는 편이 좋다.
1
| final String outputDir = ctxt.getOptions().getScratchDir().getAbsolutePath();
|
아래와 같이 나눌 수 있다.
1
2
3
| Options opts = ctxt.getOptions();
File scratchDir = opts.getScratchDir();
final String outputDir = scratchDir.getAbsolutePath();
|
- 위 예제가 디미터 법칙을 위반하는지 여부는 ctxt, Options, ScratchDir이 객체인지 아니면 자료 구조인지에 달렸다.
- 객체라면 내부 구조를 숨겨야 하므로 확실히 디미터 법칙을 위반한다.
- 반면, 자료구조라면 당연히 내부 구조를 노출하므로 디미터 법칙이 적용되지 않는다.
잡종 구조
- 위와 같은 혼란으로 말미암아 떄때로 절반은 객체, 절반은 자료구조인 잡종 구조가 나온다.
- 잡종구조는 중요한 기능을 수행하는 함수도 있고, 공개 변수나 공개 조회/설정 함수도 있다.
- 잡종구조는 새로운 함수는 물론이고 새로운 자료구조를 추가하기 어렵다.
- 양쪽 세상에서 단점만 모아놓은 구조다.
- 그러므로 잡종구조는 되도록 피하는 편이 좋다.
구조체 감추기
- 만약 ctxt, options, scratchDir 이 진짜 객체라면 앞선 예제처럼 줄줄이 사탕처럼 엮어선 안된다.
- 그렇다면 어떻게 임시 디렉토리의 절대 경로를 얻는게 좋을까?
1
2
3
| ctxt.getAbsolutePathOfScratchDirectoryOption(); // 첫번째 방법은 ctxt 객체에 공개해야 하는 메서드가 너무 많아진다.
ctxt.getScratchDirectoryOption().getAbsolutePath(); // 두번째 방법은 객체가 아니라 자료구조를 반환한다고 가정하여 썩 내키진 않는다.
|
- ctxt 객체라면 뭔가를 하라고 말해야지 속을 드러내라고 말해선 안된다.
- ctxt 객체를 통해 임시 디렉터리의 절대 경로를 얻으려는 이유가 임시 파일을 생성하기 위한 목적이라면 아래와 같이
ctxt 객체에 임시 파일을 생성하라고 시키는 것 이 가장 베스트하다.
1
| BufferedOutputStream bos = ctxt.createScratchFileStream(classFileName);
|
- 객체에 맡기기 적당한 임무로 보인다!
- ctxt 는 내부 구조를 드러내지 않으며 모듈에서 해당 함수는 자신이 몰라야 하는 여러 객체를 탐색할 필요가 없다.
- 따라서 디미터 법칙을 위반하지 않는다.
자료 전달 객체
- 일명 DTO 라 불리는 객체인데 DB와 통신하거나 소켓에서 받은 메시지의 구문을 분석시에 유용하다.
- dto는 private 변수를 getter/setter 함수로 조작한다.
- 일종의 사이비 캡슐화로, 별다른 이익을 제공하지 않는다.
활성 레코드
- 활성 레코드는 dto 의 특수한 형태다.
- 불행히도 활성 레코드에 비즈니스 규칙 메서드를 추가해 이런 자료 구조를 객체로 취급하는 개발자가 흔하다.
- 하지만 이는 바람직하지 않다.
- 그러면 자료 구조도 아니고 객체도 아닌 잡종 구조가 나오기 떄문이다.
- 해결책은 활성 레코드는 자료구조로 취급하는 것이다.
- 비즈니스 규칙을 담으면서 내부 자료를 숨기는 객체는 따로 생성한다.(여기서 내부 자료는 활성 레코드의 인스턴스일 가능성이 높다.)
결론
- 객체는 동작을 공개하고 자료를 숨긴다.
- 그래서 기존 동작을 변경하지 않으면서 새 객체 타입을 추가하기는 쉬운 반면, 기존 객체에 새 동작을 추가하기는 어렵다.
- 자료구조는 별다른 동작 없이 자료를 노출한다.
- 그래서 기존 자료 구조에 새 동작을 추가하는건 쉬우나, 기존 함수에 새 자료구조를 추가하긴 어렵다.
- 시스템을 구현할 때, 새로운 자료 타입을 추가하는 유연성이 필요하면 객체가 더 적합하다.
- 반대로 새로운 동작을 추가하는 유연성이 필요하면 자료 구조와 절차적인 코드가 더 적합하다.
- 우수한 소프트웨어 개발자는 편견없이 이 사실을 이해해 직면한 문제에 최적인 해결책을 선택한다.
예제 코드 출처
Chapter7-오류 처리
- 깨끗한 코드와 오류 처리는 확실히 연관성이 있다.
- 여기저기 흩어진 오류 처리 코드 때문에 실제 로직을 파악하기 거의 불가능해지게 된다는 의미다.
- 이는 깨끗한 코드라 부르기 어렵다.
오류 코드보다 예외를 사용하라
- 오류코드를 사용하면 로직과 오류처리가 뒤섞인다.
- 오류가 발생하면 예외를 던지는 편이 낫다. 호출자 코드가 더 깔끔해진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| //나쁜코드
public class DeviceController {
public void sendShutDown() {
DeviceHandle handle = getHandle(DEV1);
if(handle != DeviceHandle.INVALID) {
retrieveDeviceRecord(handle);
if(record.getStatus() != DEVICE_SUSPENDED) {
pauseDevice(handle);
clearDeviceWorkQueue(handle);
closeDevice(handle);
} else {
logger.log("Device suspended. Unable to shut down");
}
} else {
logger.log("Invalid handle for: " + DEV1.toString());
}
}
}
//개선 - 오류처리하는 하나의 함수를 로직을 수행하는 함수 + 예외 처리한 함수로 분리
public class DeviceController {
public void sendShutDown() {
try {
tryToShutDown();
} catch (DeviceShutDownError e) {
logger.log(e);
}
}
private void tryToShutDown() throws DeviceShutDownError {
DeviceHandle handle = getHandle(DEV1);
DeviceRecord record = retrieveDeviceRecord(handle);
pauseDevice(handle);
clearDeviceWorkQueue(handle);
closeDevice(handle);
}
}
|
Try-Catch-Finally 문부터 작성하라
- try 블록은 트랜잭션과 비슷하다.
- 무슨 일이 생기든 catch 블록은 프로그램 상태를 일관성 있게 유지해야 한다.
- 그러므로 예외가 발생할 코드를 짤 땐 try-catch-finally 문부터 시작하는 편이 낫다.
- try 블록에서 무슨 일이 생기든지 호출자가 기대하는 상태를 정의하기 쉬워진다.
- 강제로 예외를 일으키는 테스트 케이스를 작성한 후 테스트를 통과하게 코드를 작성하는 방법이 좋다.
- 자연스럽게 try 블록의 트랜잭션 범위부터 구현하게 되므로 범위 내에서 트랜잭션 본질을 유지하기 쉬워진다.
미확인 예외를 사용하라
- 확인된 예외는 OCP(Open Closed Principle) 를 위반하다.
- 메서드에서 확인 예외를 던지더라도 catch 블록이 여러 단계 위에 있다면 그 사이 메서드 모두가 예외를 정의해야 한다. (
throw Exception)- 즉, 하위 단계 메서드의 코드를 변경시 상위 단계 메서드 선언부를 전부 고쳐야 한다는 말이다.
- 딘계를 내려갈수록 호출하는 함수 수는 늘어난다. throws 경로에 위치하는 모든 함수가 예외를 알아야하므로 캡슐화가 깨진다.
- 확인된 예외도 유용하지만 일반적인 애플리케이션은 의존성이라는 비용이 이익보다 크다.
예외에 의미를 제공하라
- 예외를 던질 땐 전후 상황을 충분히 덧붙인다.
- 그러면 오류 발생 원인과 위치를 찾기 쉬워진다.
- 자바는 모든 예외에 호출 스택을 제공하지만 실패한 코드의 의도를 파악하려면 호출 스택만으론 부족하다.
- 오류 메시지에 정보를 담아 예외와 함께 던지는게 좋다.
- 실패한 연산 이름과 실패 유형도 언급한다.
- 애플리케이션이 로깅 기능을 사용한다면 catch 블록에서 오류를 기록하도록 충분한 정보를 넘겨준다.
호출자를 고려해 예외 클래스를 정의하라
- 애플리케이션에서 오류를 정의할 때 프로그래머에게 가장 중요한 관심사는
오류를 잡아내는 방법 이 되어야 한다. - 외부 API를 사용할 때는 감싸기 기법을 사용하면 외부 라이브러리와 프로그램 사이에서 의존성이 크게 줄어든다.
- 또한 나중에 다른 라이브러리로 갈아타도 비용이 적다.
감싸기(Wrapper) 클래스에서 외부 API를 호출하는 대신 테스트 코드를 넣어주는 방법으로 프로그램을 테스트하기도 쉬워진다.- 마지막으로 특정 업체가 API 를 설계한 방식에 발목 잡히지 않는다. 프로그램이 사용하기 편리한 API를 정의하면 그만이기 때문이다.
- 한 예외는 잡아내고 다른 예외는 무시해도 괜찮은 경우라면 여러 예외 클래스를 사용하도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| //나쁜 예시 - 예외에 대응하는 방식이 예외 유형과 무관하게 거의 동일하다.
ACMEPort port = new ACMEPort(12);
try {
port.open();
} catch (DeviceResponseException e) {
reportPortError(e);
logger.log("Device response exception", e);
} catch (ATM1212UnlockedException e) {
reportPortError(e);
logger.log("Unlock exception", e);
} catch (GMXError e) {
reportPortError(e);
logger.log("Device response exception");
} finally {
....
}
//개선 - 예외를 잡아 유형을 반환하는 감싸기(wrapper) 클래스로 의존성 최소화
LocalPort port = new LocalPort(12);
try {
port.open();
} catch (PortDeviceFailure e) {
reportPortError(e);
logger.log(e.getMessage(), e);
} finally {
....
}
public class LocalPort {
private ACMEPort innerPort;
public LocalPort(int portNumber) {
innerPort = new ACMEPort(portNumber);
}
public void open() {
try {
innerPort.open();
} catch (DeviceResponseException e) {
throw new PortDeviceFailure(e);
} catch (ATM1212UnlockedException e) {
throw new PortDeviceFailure(e);
} catch (GMXError e) {
throw new PortDeviceFailure(e);
}
}
}
|
정상 흐름을 정의하라
- 예외는 논리를 따라가기 어렵게 만든다.
- 가장 좋은 것은 특수 상황을 처리할 필요가 없는 것이다.
- 특수 사례 패턴은 클래스를 만들거나 객체를 조작해 특수 사례를 처리하는 방식이다.
- 특수 사례 패턴은 클래스나 객체가 예외적인 상황을 캡슐화해서 처리하므로 클라이언트 코드가 예외적인 상황을 처리할 필요가 없게 만든다.
- 아래 예시에선
PerDiemMealExpenses 클래스에 해당한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| //나쁜 예시
try {
MealExpenses expenses = expenseReportDAO.getMeals(employee.getID());
m_total += expenses.getTotal();
} catch (MealExpenseNotFound e) {
m_total += getMealPerdiem();
}
//개선 - 특수 사례 패턴으로 예외를 처리할 필요가 없게 만듦.
MealExpenses expenses = expenseReportDAO.getMeals(employee.getID());
m_total += expenses.getTotal();
public class PerDiemMealExpenses implements MealExpenses {
public int getTotal() {
//기본값으로 일일 기본 식비는 반환하는 코드
}
}
|
null을 반환하지마라.
- null을 반환하는 코드는 일거리를 늘릴 뿐만 아니라 호출자에게 문제를 떠넘긴다.
- 누구 하나라도 null 확인을 빼먹는다면 애플리케이션이 통제 불능에 빠질지도 모른다.
- 메서드에서 null을 반환하고픈 유혹이 든다면 예외를 던지거나 특수 사례 객체를 반환한다.
- 사용하려는 외부 API가 null을 반환한다면 감싸기 메서드를 구현해 예외를 던지거나 특수 사례 객체를 반환하는 방식을 고려한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| //나쁜 코드 - null을 반환하는 getEmployees메서드.
List<Employee> employees = getEmployees();
if(employees != null) {
for(Employee e : employees) {
totalPay += e.getPay();
}
}
//개선 - getEmployee 메서드가 null이 아닌 빈 List를 반환하도록 수정한다. 코드가 훨씬 깔끔해지고 NPE 가 발생할 가능성도 줄어든다!
List<Employee> employees = getEmployees();
for(Employee e : employees) {
totalPay += e.getPay();
}
public List<Employee> getEmployees() {
if(...) //직원이 없다는 것을 확인하는 조건문
return Collections.emptyList();
}
|
null을 전달하지 마라
- 메서드 인수로 null을 전달하는 방식은 더 나쁘다.
1
2
3
4
5
6
7
8
| public class MetricsCalculator {
public double xProjection(Point p1, Point p2) {
return (p2.x - p1.x) * 1.5;
}
...
}
calculator.xProject(null, new Point(12, 13)); // NPE 발생!!!
|
- 위와 같은 NPE 를 방지하려면
새로운 예외 유형을 만들어 던지거나, assert 문을 사용하여 메서드 내부에서 방어를 할 수 있을 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class MetricsCalculator {
public double xProjection(Point p1, Point p2) {
if (p1 == null || p2 == null) {
throw INvalidArgumentException("Invalid argument for MetricsCalculator.xProjection");
}
return (p2.x - p1.x) * 1.5;
}
...
}
public class MetricsCalculator {
public double xProjection(Point p1, Point p2) {
assert p1 != null : "p1 should not be null";
assert p2 != null : "p2 should not be null";
return (p2.x - p1.x) * 1.5;
}
...
}
|
- 하지만 위와 같은 방법들은 누군가 null을 전달하면 실행 오류가 발생하게 되어 문제를 해결하진 못한다.
- 대다수 프로그래밍 언어는 호출자가 실수로 넘기는 null을 적절히 처리하는 방법이 없다.
- 애초에 null을 넘기지 못하도록 금지하는 정책이 합리적이다.
- 즉, 인수로 null이 넘어오면 코드에 문제가 있다는 말이다.
- 이런 정책을 따르면 그만큼 부주의한 실수를 저지를 확률도 작아진다.
결론
- 깨끗한 코드는 읽기도 좋아야 하지만 안정성도 높아야 한다.
- 이 둘은 상충하는 목표가 아니다.
- 오류 처리를 프로그램 논리와 분리해 독자적인 사안으로 고려하면 튼튼하고 깨끗한 코드를 작성할 수 있다.
- 오류 처리를 프로그램 논리와 분리하면 독립적인 추론이 가능해지며 코드 유지보수성도 크게 높아진다.
Reference
Chapter8-경계
- 시스템에 들어가는 모든 소프트웨어를 직접 개발하는 경우는 드물다.
- 때로는 패키지를 사고, 오픈 소스를 이용한다.
- 때로는 사내 다른 팀이 제공하는 컴포넌트를 사용한다.
- 어떤 식으로든 이 외부 코드를 우리 코드에 깔끔하게 통합해야만 한다.
- 이 장에선 소프트웨어 경계를 깔끔하게 처리하는 기법과 기교를 살펴본다.
외부 코드 사용하기
- 패키지 제공자나 프레임워크 제공자는 적용성을 최대한 넓히려 애쓴다.
- 이를 사용하는 클라이언트 사용자는 자신의 요구에 집중하는 인터페이스를 바란다.
- 이러한 긴장으로 인해 시스템 경계에서 문제가 생길 소지가 많다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| //나쁜 코드 - 형변환이 매번 있으며 sensors의 권한이 사용하는 모두에게 존재함.
// 누군가는 Map 이 제공하는 clear 를 호출해서 Map 의 담겨져있는 데이터를 전부 날릴 수 있음
Map sensors = new HashMap();
Sensor s = (Sensor)sensors.get(sensorId);
//Generics 사용하여 개선 - 코드 가독성은 높아지지만 권한 문제는 해결x
// Map 인터페이스가 변경되면 수정해야할 부분이 생긴다.
Map<String, Sensor> sensors = new HashMap<Sensor>();
Sensor s = sensors.get(sensorId);
//Map을 캡슐화하는 Sensors 클래스 정의하여 개선 - 캡슐화를 통해 권한 문제도 해결할 수 있음.
public class Sensors {
private Map sensors = new HashMap();
public Sensor getById(String id) {
return (Sensor)sensors.get(id);
}
}
|
- 외부 API를 캡슐화하면 나머지 프로그램이 설계 규칙과 비즈니스 규칙을 따르도록 강제할 수 있다.
- Map 클래스를 사용할때마다 캡슐화를 하라는게 핵심이 아니다. Map을 여기저기 넘기지 말라는것이 핵심이다.
- Map과 같은 경계 인터페이스를 이용할때는 이를 이용하는 클래스나 클래스 계열 밖으로 노출되지 않도록 주의한다.
- Map 인스턴스를 공개 API의 인수로 넘기거나 반환값으로 사용하지 않는다.
경계 살피고 익히기
- 외부 패키지 테스트가 우리 책임은 아니지만 우리 자신을 위해 우리가 사용할 코드를 테스트하는 편이 바람직하다.
- 외부 코드를 익히긴 어렵다. 외부 코드를 통합하기 또한 어렵다. 이 두 가지를 동시에 하기는 두 배나 어렵다.
- 다르게 접근하면 어떨까? 곧바로 우리쪽 코드를 작성해 외부 코드를 호출하는 대신 먼저 간단한 테스트 케이스를 작성해 외부 코드를 익히면 어떨까? 짐 뉴커크는 이를
학습테스트라 부른다.
학습테스트
- 학습 테스트는 프로그램에서 사용하려는 방식대로 외부 API를 호출한다.
- 학습 테스트는 다음의 순서대로 진행한다.
- 1)외부 패키지의 문서를 자세히 읽기 전에 첫 번째 테스트 케이스를 작성한다.
- 2)오류를 해결하기 위해 문서를 읽고 테스트를 해결한다.
- 3)얻은 지식을 토대로 간단한 단위 테스트 케이스들이 담긴 테스트 클래스로 표현한다.
- 테스트 클래스로부터 얻은 지식을 바탕으로 독자적인 클래스로 외부 API를 캡슐화한다.
- 학습테스트는 필요한 지식만 확보하는 손쉬운 방법이다.
- 패키지 새 버전이 나오면 학습 테스트를 돌려 차이가 있는지 확인할 수 있다.
- 학습테스트만 돌려도 우리 코드와 호환되는지 확인 가능하다.
- 이러한 경계 테스트가 있다면 패키지의 새 버전으로 이전하기 쉬워진다.
- 만약 반대로 없다면 낡은 버전을 필요 이상으로 오랫동안 사용하려는 유혹에 빠지기 쉽다.
아직 존재하지 않는 코드를 사용하기
- 때로는 우리 지식이 경계를 너머 미치지 못하는 코드 영역도 있다.
- 코드를 작성하는 우리는 경계가 어딘쯤인지 대략적으로 알 수 있다.(필요한 경계 인터페이스를 찾을 수 있음)
- 자체적으로 우리가 바라는 인터페이스를 정의하자.
어댑터 패턴 (ADAPTER PATTERN)
- 어댑터 패턴은 클래스의 인터페이스를 사용자가 기대하는 다른 인터페이스로 변환하는 패턴이다.
- 우리가 바라는 인터페이스를 구현하면 우리가 인터페이스를 전적으로 통제한다는 장점이 생긴다.
- 코드 가독성도 높아지고 코드 의도도 분명해진다.
- API 사용을 캡슐화해 API가 바뀔 때 수정할 코드를 한곳으로 모아 응집도를 높일 수 있다.
- 테스트도 아주 편하다. 실제 Transmitter API 가 나온 다음 경계 테스트 케이스를 생성해 API를 올바로 사용하는지 테스트할 수도 있다.
출처: https://haeng-on.tistory.com/69
- 어댑터 패턴과 관련된 내용은 아래 링크를 참고하면 더 자세한 내용을 알 수 있다.
깨끗한 경계
- 소프트웨어 설계가 우수하다면 변경하는데 많은 투자와 재작업이 필요치 않다.
- 통제하지 못하는 코드를 사용할 땐 너무 많은 투자를 하거나 향후 변경 비용이 지나치게 커지지 않도록 각별히 주의해야 한다.
- 경계에 위치하는 코드는 깔끔히 분리한다.
- 통제가 불가능한 외부 패키지에 의존하는 대신 통제가 가능한 우리 코드에 의존하는 편이 훨씬 좋다. 자칫하면 외부 코드에 휘말린다..
- 외부 패키지를 호출하는 코드를 가능한 줄여 경계를 관리하자.
- Map 에서 봤듯이, 새로운 클래스로 경계를 감싸거나 아니면 ADAPTER 패턴을 사용해 우리가 원하는 인터페이스를 패키지가 제공하는 인터페이스로 변환하자.
- 어느 방법이든 코드 가독성이 높아지며, 경계 인터페이스를 사용하는 일관성도 높아지며, 외부 패키지가 변했을 때 변경할 코드도 줄어든다.
Reference
Chapter9-단위 테스트
- 아주 예전 개발자들은 실제 코드가 돌아간다는 사실을 확인하고 테스트 코드를 버렸다.
- 하지만 지금 같은 경우엔 코드가 제대로 도는지 황긴하는 테스트 코드를 수 없이 작성하고, 모든 테스트 케이스를 통과한 후엔 실제 제품 코드와 같은 소스 패키지로 확실하게 묶는다.
- 하지만 많은 프로그래머들이 제대로 된 테스트 케이스를 작성해야 한다는 좀 더 미묘한 (그리고 더욱 중요한) 사실을 놓쳐버렸다.
TDD 세 가지 법칙
- TDD 는 실제 코드를 짜기 전에 단위 테스트부터 짜라고 요구한다.
- 이 외에 다음 세 가지 법칙을 살펴보자.
- 1)첫번째 법칙: 실패하는 단위 테스트를 작성할 때까지 실제 코드를 작성하지 않는다.
- 2)둘째 법칙: 컴파일은 실패하지 않으면서 실행이 실패하는 정도로만 단위 테스트를 작성한다.
- 3)셋째 법칙: 현재 실패하는 테스트를 통과할 정도로만 실제 코드를 작성한다.
- 위 세 가지 규칙을 따르면 개발과 테스트가 대략 30초 주기로 묶인다.
- 테스트 코드와 실제 코드가 함께 나올뿐더러 테스트 코드가 실제 코드보다 불과 몇 초 전에 나온다.
- 이렇게 일하면 매일 수십개, 매달 수백개, 매년 수천 개에 달하는 테스트 케이스가 나온다.
- 이렇게 이랗면 실제 코드를 사실상 전부 테스트하는 테슽트 케이스가 나온다.
- 하지만 실제 코드와 맞먹을 정도로 방대한 테스트 코드는 심각한 관리 문제를 유발하기도 한다…
✨깨끗한 테스트 코드 유지하기✨
- 지저분한 테스트 코드를 내놓는 것은 테스트를 안 하는 것보다 더 못하다.
- 문제는 실제 코드가 진화하면 테스트 코드도 변해야 한다는데 있다.
- 그런데 테스트 코드가 지저분할수록 변경이 어려워진다.
- 테스트 코드가 복잡할수록 실제 코드를 짜는 시간보다 테스트 케이스를 추가하는 시간이 더 걸리기 십상이다.
- 실제 코드를 변경해 기존 테스트 케이스가 실패하기 시작하면, 지저분한 코드로 인해, 실패하는 테스트 케이스를 점점 더 통과하기 어려워진다.
- 그래서 테스트 코드는 계속해서 늘어나는 부담이 된다..
- 그렇다고 테스트 슈트가 없으면 개발자는 자신이 수정한 코드가 제대로 도는지 확인할 방법이 없다.
- 시스템 이쪽을 수정해도 저쪽이 안전하다는 사실을 검증하지 못한다.
- 그래서 시스템이 커질수록 결함율이 높아지기 시작하고 의도하지 않은 결함 수가 많아지면 개발자는 변경을 주저하게 된다.
- 변경하면 득보다 해가 더 크다 생각해 더 이상 코드를 정리하지 않게 되고 코드가 망가지기 시작한다..
- 결국 테스트 슈트도 없고, 얼기설기 뒤섞인 코드에, 좌절한 고객과 테스트에 쏟아 부은 노력이 허사였다는 실망감만 남게 된다….
- 이러한 현상의 근본적인 원인은 테스트 코드를 막 짜도 좋다고 허용한 결정 및 마인드다.
- 필자가 위와 같이 얘기하는 이유는 필자가 참여하고 조언한 많은 팀이 깨끗한 단위 테스트 코드로 성공했기 때문이다.
- 테스트 코드는 실제 코드 못지 않게 중요하고 깨끗하게 짜야한다.
- 이류 시민이 아니다.
- 사고와 설계와 주의가 필요하다.
테스트는 유연성, 유지보수성, 재사용성을 제공한다.
- 테스트 코드를 깨끗하게 유지하지 않으면 결국은 잃어버리고 테스트케이스가 없으면 실제 코드를 유연하게 만드는 버팀목도 사라진다.
- 코드에 유연성, 유지보수성, 재사용성을 제공하는 버팀목이 바로 단위 테스트다.
- 이유는 단순하다. 테스트 케이스가 있으면 변경이 두렵지 않기에!!!
깨끗한 테스트 코드
- 가독성만 있으면 되고 이는 명료성, 단순성, 풍부한 표현력이 필요하다.
- 테스트 코드는 최소의 표현으로 많은것을 나타내야 한다.
- 테스트 코드와 무관하며 테스트 코드의 의도를 흐리는것은 제거해야한다. (p.159 목록9-1 참고)
- BUILD-OPERATE-CHECK 패턴을 위 케이스에 적절히 활용하자. 첫 부분은 테스트 자료를 만들고 두번째 부분은 테스트 자료를 조작하며, 세번째 부분은 조작한 결과가 올바른지 확인하는 패턴이다. (p.160 목록9-2 참고)
- 코드를 읽는 사람을 위해 잡다하고 세세한 코드를 없애도록 하자. 테스트 코드는 본론에 돌입해 진짜 필요한 자료 유형과 함수만(ex. ` WikiPage page = makePage(“pageOne”); makePages(“PageOne.ChildOne”, “PageTwo”);`)사용한다.
이중 표준
- 테스트코드는 단순하고, 간결하고, 표현력이 풍부해야 하지만, 실제 코드만큼 효율적일 필요는 없다.
- 실제 환경이 아닌 테스트 환겨엥서 돌아가기 때문이다.
- 일부 그릇된 정보를 나타내는 테스트 코드더라도 적절할때가 있다. 일단 의미만 안다면 눈길이 문자열을 따라 움직이며 결과를 재빨리 판단하게 되기 때문인다. 테스트 코드를 읽기가 즐거워지고 이해하기 쉬워진다. (p.162 목록9-4)
- StringBuffer 는 보기흉한다. 실제 코드에서도 저자는 크게 무리가 가지 않는선에서 StringBuffer를 피한다. 하지만 테스트 코드에선 자원이 제한적일 가능성이 낮기에 큰 상관없다.
- 이것이 ‘이중 표준’의 본질이다. 실제 환경에선 절대로 안되지만 테스트 환경에선 전혀 문제 없는 방식이 있다. 대개 메모리나 CPU 효율과 관련 있는 경우다. 코드의 깨끗함과는 철절히 무관한다.
테스트당 assert 하나
- 함수마다 assert문을 단하나만 사용해야 한다고 주장하는 학파가 있다. 결론이 하나라 코드를 이해하기 쉽고 빠르다는 주장이다.
- 하지만 그렇게 하면 중복 코드가 많아져 templte method 패턴과 @Before 함수에 given, when 절을 넣어 중복 코드를 해결하게되는데 이는 배보다 배꼽이 더 큰 격이다.
- 이를 감안하면 저자는 assert 문을 여럿 사용하는 편이 좋다 생각하며 최대한 assert 문을 줄이는걸 지양해야 한다고 한다.
테스트당 개념 하나
- 가장 좋은 규칙은 “개념 당 assert 문 수를 최소로 줄여라”와 “테스트 함수는 하나는 개념 하나만 테스트하라” 이다.
FIRST
- Fast(빠르게): 테스트는 빨라야 한다. 느리면 자주 돌릴 엄두를 못 내게 되어 초반에 문제를 찾아 고치지 못한다. 그리고 코드를 마음껏 정리하지도 못하게 된다.
- Independent(독립적으로): 각 테스트는 서로 의존하면 안된다. 한 테스트가 다음 테스트가 실행될 환경을 준비해선 안된다. 이렇게 되면 원인이 어디서 발생했는지 찾기 어려워진다.
- Repeatable(반복 가능하게): 어떤 환경에서든 반복 가능해야 한다. 테스트가 실패한 이유를 환경 탓으로 돌리게 해선 안된다.
- Self-Validating(자가 검증하는): 부울(bool)값으로 결과를 내야 한다. 성공 아니면 실패다. 통과 여부를 알려고 로그 파일을 읽어선 안된다. 테스트 성공 여부에 대한 판단이 주관적이 되어 수작업 평가가 필요해져선 안된다.
- Timley(적시에): 적시에 작성해야 한다. 단위 테스트는 실제 코드를 구현하기 직전에 구현한다. 실제 코드를 구현한 다음에 테스트 코드를 만들면 실제 코드가 어렵다는 사실을 발견할지도 모른다.
결론
- 테스트 코드는 실제 코드만큼이나 프로젝트 건강에 중요하다.(어쩌면 더 중요할지도)
- 실제 코드의 유연성, 유지보수성, 재사용성을 보존하고 강화하기 때문이다.
- 그러므로 테스트 코드는 지속적으로 깨끗하게 관리하자. 표현력을 높이고 간결하게 정리하자.
- 테스트 API를 구현해 도메인 특화 언어(Domain Specific Language, DSL)를 만들자. 그러면 그만큼 테스트 코드를 짜기가 쉬워진다.
Reference
Chapter10-클래스
클래스 체계
- 클래스의 구성원 변수 목록 -> 함수순으로 구성된다.
- 정적 공개 상수(static public) -> 정적 비공개(private static)변수가 나오게되고 그다음 비공개 인스턴스 변수가 나온다. 공개 변수가 필요한 경우는 거의 없다.
- 함수는 공개 함수가 나오고 비공개 함수는 자신을 호출하는 공개 함수 직후에 넣는다. 즉, 추상화 단계가 순차적으로 내려간다. 그래서 프로그램은 신문 기사처럼 읽힌다.
캡슐화
- 때로는 변수나 유틸리티 함수를 protected 로 선언해 테스트 코드에 접근을 허용하기도 한다.
- 같은 패키지 안에서 테스트 코드가 함수를 호출하거나 변수를 사용해야 한다면 그 함수나 변수를 protected 로 선언하거나 패키지 전체로 공개한다.
- 하지만 그 전에 비공개 상태를 유지할 온갖 방법을 강구한다. 캡슐화를 풀어주는 결정은 언제 최후의 수단이다.
클래스는 작아야 한다!
- 클래스의 크고 작음을 판단하는 지표는 많은 책임의 수이다. (함수의 수 x)
- 목록 10-1 예제 참고
- 클래스 이름은 해당 클래스 책임을 기술해야 한다. 실제로 작명은 클래스 크기를 줄이는 첫 번째 관문이다.
- 클래스 이름이 모호하다면 클래스 책임이 너무 많아서다.
- 예를 들어, 클래스 이름에 Processor, Manager, Super 등고 ㅏ같이 모호한 단어가 있다면 클래스에 여러 책임을 떠안겼다는 증거다.
- 또한 클래스 설명은 만일(“if”), 그리고(“and”), -(하)며(“or”), 하지만(“but”)을 사용하지 않고서 25단어 내외로 가능해야 한다.
단일 책임 원칙(SRP)
- 클래스나 모듈을 변경할 이유(책임)가 단 하나뿐이어야 한다는 원칙이다.
- 책임, 즉 변경할 이유를 파악하려 애쓰다 보면 코드를 추상화하기도 쉬워진다.
- 그럼에도 우리는 수많은 책임을 떠안은 클래스를 꾸준하게 접한다. 왜일까??
- 소프트웨어를 돌아가게 만드는 활동과 깨끗하게 만드는 활동은 완전히 별개다.
- 우리들 대다수가 프로그램이 돌아가면 일이 끝났다고 여기기에 수많은 책임을 떠안은 만능 클래스가 나오게 되는것이다.
- ‘깨끗하고 체계적인 소프트웨어’ 라는 다음 관심사로 전환하지 않고서 말이다.
- 규모가 어느 수준에 이르는 시스템은 논리가 많고 복잡한데 이런 복잡성을 다루려면 체계적인 정리가 필수적이다.
응집도(Cohesion)
- 클래스는 인스턴스 변수 수가 작아야 한다. 각 클래스 메서드는 클래스 인스턴스 변수를 하나 이상 사용해야 한다.
- 일반적으로 메서드가 변수를 더 많이 사용할수록 메서드와 클래스는 응집도가 더 높다.
- 응집도가 높다는 말은 클래스에 속한 메서드와 변수가 서로 의존하며 논리적인 단위로 묶인다는 의미기 때문이다.
- ‘함수를 작게, 매개변수 목록을 짧게’ 라는 전략을 따르다 보면 때때로 몇몇 메서드만이 사용하는 인스턴스 변수가 아주 많아진다. 이는 십중팔구 새로운 클래스로 쪼개야 한다는 신호다. 응집도가 높아지도록 변수와 메서드를 적절히 분리해 새로운 클래스 두세 개로 쪼개준다.
응집도를 유지하면 작은 클래스 여럿이 나온다.
- 큰 함수를 작은 함수 여럿으로 나누기만 해도 클래스 수가 많아진다.
- 예를 들어, 변수가 아주 많은 큰 함수 하나가 있다.
- 큰 함수 일부를 작은 함수로 빼내고 싶은데, 빼내려는 코드가 큰 함수에 정의된 변수 넷을 사용한다. 그렇다면 변수 네 개를 새 함수에 인수로 넘겨야 옳을까?
- 전혀 아니다! 만약 네 변수를 클래스 인스턴스 변수로 승격한다면 새 함수는 인수가 필요없다. 그만큼 함수를 쪼개기 쉬워진다.
- 불행히도 이렇게 하면 클래스가 응집력을 잃는다. 몇몇 함수만 사용하는 인스턴스 변수가 점점 더 늘어나기 때문이다.
- 몇몇 함수가 몇몇 변수만 사용한다면 독자적인 클래스로 분리하면 된다. 클래스가 응집력을 잃는다면 쪼개라!
- 그래서 큰 함수를 작은 함수 여럿으로 쪼개다 보면 종종 작은 클래스 여럿으로 쪼갤 기회가 생긴다. 그러면서 프로그램에 점점 더 체계가 잡히고 구조가 투명해진다.
- 목록 10-5 예제를 리팩토링한 부분 참고
- 리팩토링한 결과 길이가 늘어난 이유는 여러 가지다.
- 첫째, 리팩터링한 프로그램은 좀 더 길고 서술적인 변수 이름을 사용한다.
- 둘째, 리팩터링한 프로그램은 코드에 주석을 추가하는 수단으로 함수 선언과 클래스 선언을 활용한다.
- 셋째, 가독성을 높이고자 공백을 추가하고 형식을 맞추었다.
- 리팩터링은 원래 프로그램의 정확한 동작을 검증하는 테스트 슈트를 작성했다. 그 다음, 한 번에 하나씩 수 차례에 걸쳐 조금씩 코드를 변경했다. 코드를 변경할 때마다 테스트를 수행해 원래 프로그램과 동일하게 동작하는지 확인했다. 조금씩 원래 프로그램을 정리한 결과 최종 프로그램으로 완성하였다.
변경하기 쉬운 클래스
- 깨끗한 시스템은 클래스를 체계적으로 정리해 변경에 수반하는 위험을 낮춘다.
- 목록10-9, 10-10 예제 참고
- 경험에 의하면 클래스 일부에서만 사용되는 비공개 메서드는 코드를 개선할 잠재적인 여지를 시사한다. 하지만 실제로 개선에 뛰어드는 계기는 시스템이 변해서라야 한다. Sql 클래스를 논리적 완성으로 여긴다면 책임을 분리하려 시도할 필요가 없다. 가까운 장래에 update 문이 필요치 않다면 Sql 클래스를 내버려두는 편이 좋다. 하지만 클래스에 손대는 순간 설계를 개선하려는 고민과 시도가 필요하다.
- 모든 파생 클래스가 공통으로 사용하는 비공개 메서드는 Where 과 ColumnList 라는 두 유틸리티 클래스에 넣었다.
- 목록10-10으로 변경후에 각 클래슨느 극도로 단순해졌다. 코드는 순식간에 이해된다. 함수 하나를 수정했다고 다른 함수가 망가질 위험도 사실상 사라졌다. 테스트 관점에서 모든 논리를 구석구석 증명하기도 쉬워졌다. 클래스가 서로 분리되었기 때문이다.
- update 문을 추가할 때 기존 클래스를 변경할 필요가 전혀 없다는 사실 역시 중요하다! update 문을 만드는 논리는 Sql 클래스에서 새 클래스 UpdateSql 을 상속받아 거기에 넣으면 그만이다. update 문을 지원해도 다른 코드가 망가질 염려는 전혀 없다.
- 새 기능을 수정하거나 기존 기능을 변경할 때 건드릴 코드가 최소인 시스템 구조가 바람직하다. 이상적인 시스템이라면 새 기능을 추가할 때 시스템을 확장할 뿐 기존 코드를 변경하지 않는다.
변경으로부터 격리
- 상세한 구현에 의존하는 코드는 테스트가 어렵다.
- 그 예시로 Portfolio 예제처럼 실제 외부에 API호출을 통해 받아오도록 구현하면 테스트가 어렵다. 왜? 시시각각 값이 달라지기 떄문이다.
- 이때 외부에서 API 호출하여 데이터 받아오는 부분을 인터페이스로 추상화시켜 Portfolio 는 해당 인터페이스에 의존하도록 구현하면 테스트시 특정 값을 내려주는 더미 구현체를 주입하면 된다.
- 이처럼 테스트가 가능할 정도로 시스템의 결합도를 낮추면 유연성과 재사용성도 더욱 높아진다. 결합도가 낮다는 소리는 각 시스템 요소가 다른 요소로부터 그리고 변경으로부터 잘 격리되어 있다는 의미다.
- 시스템 요소가 서로 잘 격리되어 있으면 각 요소를 이해하기도 더 쉬워진다.
- 결합도를 최소로 줄이면 자연스럽게 또 다른 클래스 설계 원칙인 DIP(클래스가 상세한 구현이 아닌 추상화에 의존해야 한다는 원칙)를 따르는 클래스가 나오게 된다.
Reference
Chapter11-시스템
“복잡성은 죽음이다. 개발자에게서 생기를 앗아가며, 제품을 계획하고 제작하고 테스트하기 어렵게 만든다.” - 레이 오지, 마이크로소프트 CTO
도시를 세운다면?
- 이 장에선 높은 추상화 수준, 즉 시스템 수준에서도 깨끗함을 유지하는 방법을 살펴본다.
시스템 제작과 시스템 사용을 분리하라
소프트웨어 시스템은 (애플리케이션 객체를 제작하고 의존성을 서로 ‘연결’ 하는) 준비 과정과 (준비 과정 이후에 이어지는) 런타임 로직을 분리해야 한다.
1
2
3
4
5
6
| public Service getService() {
if(service == null) {
service = new MyServiceImpl(...); // 모든 상황에 적합한 기본값일까?
}
return service;
}
|
- 초기화 지연(Lazy Initialization), 계산 지연 기법(Lazy Evaluation) 이다.
- 필요할 때까지 객체를 생성하지 않으므로 애플리케이션 시작이 빨라지고, 어떠한 경우에도 null포인터를 반환하지 않는다.
- 위 코드가 나쁜 코드인 이유는 아래와 같다.
- 준비 과정 코드를 런타임 로직과 분리하지 않음
- getService 메서드가 MyServiceImpl에 의존성을 갖음
- getService 메서드가 MyServiceImpl을 생성하는 행위와 service 객체를 리턴하는 행위를 동시에 수행 (SRP 위반)
- MyServiceImpl을 생성하는 것이 모든 상황에 적합한 객체인지 알 수 없음
- 한 번 정도 사용한다면 별로 심각한 문제는 아니지만 이처럼 좀스러운 설정 기법을 수시로 사용하는게 문제고 전반적인 설정 방식이 애플리케이션 곳곳에 흩어지게 된다. 모듈성은 저종하며 대개 중복이 심각해진다.
- 체계적이고 탄탄한 시스템을 만들고 싶다면 흔히 쓰는 좀스럽고 손쉬운 기법으로 모듈성을 깨선 절대로 안된다.
- 객체를 생성하거나 의존성을 연결할때도 마찬가지다. 설정 논리는 일반 실행 논리와 분리해야 모듈성이 높아진다. 또한 주요 의존성을 해소하기 위한 방식, 즉 전반적이며 일관적인 방식도 필요하다.
Main 분리
- 시스템 생성과 시스템 사용을 분리하는 한 가지 방법으로, 생성과 관련한 코드는 모두 main 이나 main 이 호출하는 모듈로 옮기고, 나머지 시스템은 모든 객체가 생성되었고 모든 의존성이 연결되었다고 가정한다. (아래 이미지 참고)
- spring 프레임워크도 애플리케이션 기동시 모든 bean 을 생성하고 의존성이 맺어진 상태에서 동작하는것도 같은 맥락일것 같다.
출처: https://hirlawldo.tistory.com/145
- 제어 흐름은 따라가기 쉽다. main 함수에서 시스템에 필요한 객체를 생성한 후 이를 애플리케이션에 넘긴다. 애플리케이션은 그저 객체를 사용할 뿐이다.
- main 과 애플리케이션 사이에 표시된 의존성 화살표는 main 쪽에서 애플리케이션쪽을 향한다.
- 즉, 애플리케이션은 main 이나 객체가 생성되는 과정을 전혀 모른다는 뜻이다. 단지 모든 객체가 적절히 생성되었다고 가정하여 동작한다.
팩토리
- 물론 때로는 객체가 생성되는 시점을 애플리케이션이 결정해야할 필요도 생긴다.
- 예를 들어, 주문 처리 시스템에서 어플리케이션은 LineItem 인스턴스를 생성해 Order에 넘긴다. 이때는 Abstract Factory 패턴을 사용한다. 그러면 LineItem을 생성하는 시점은 어플리케이션이 결정하지만 LineItem을 생성하는 코드는 어플리케이션이 모른다.
출처: https://hirlawldo.tistory.com/145
- 여기서도 마찬가지로 모든 의존성이 main에서 OrderProcessing 어플리케이션으로 향한다.
- 즉, OrderProcessing 어플리케이션은 LineItem이 생성되는 구체적인 방법은 모른다. 그 방법은 LineItemFactoryImplementation이 안다. 그럼에도 OrderProcessing 어플리케이션은 LineItem 인스턴스가 생성되는 시점을 완벽하게 통제하며, 필요하다면 OrderProcessing 어플리케이션에서 사용하는 생성자 인수도 넘길 수 있다.
의존성 주입
- 사용과 제작을 분리하는 강력한 메커니즘 하나가 의존성 주입(Dependency Injection, DI)이다. 의존성 주입은 제어 역전 기법을 의존성 관리에 적용한 메커니즘이다.
- 의존성 관리 맥락에서 객체는 의존성 자체를 인스턴스로 만드는 책임은 지지 않는다. 대신 이런 책임을 다른 ‘전담’ 메커니즘에 넘겨야만 하고 그렇게 함으로써 제어를 역전한다.
- 초기 설정은 시스템 전체에서 필요하므로 대개 ‘책임질’ 메커니즘으로 ‘main’ 루틴이나 특수 컨테이너를 사용한다.
확장
- ‘처음부터 올바르게’ 시스템을 만들 수 있다는 믿음은 미신이다. 대신에 우리는 오늘 주어진 사용자 스토리에 맞춰 시스템을 구현해야 한다. 내일은 새로운 스토리에 맞춰 시스템을 조정하고 확장하면 된다. 이것이 반복적이고 점진적인 애자일 방식의 핵심이다. TDD, 리팩터링으로 얻어지는 깨끗한 코드는 코드 수준에서 시스템을 조정하고 확장하기 쉽게 만든다.
소프트웨어 시스템은 관심사를 적절히 분리해 관리한다면 소프트웨어 아키텍처는 점진적으로 발전 가능하다.
횡단(cross-cutting) 관심사
- 원론적으로 모듈화되고 캡슐화된 방식으로 영속성 방식을 구상할 수 있다. 하지만 현실적으로 영속성 방식을 구현한 코드가 온갖 객체로 흩어진다.
- AOP에서 특정 관점(Aspect)라는 모듈 구성 개념은 “특정 관심사를 지원하려면 시스템에서 특정 지점들이 동작하는 방식을 일관성 있게 바꿔야 한다”라고 명시한다.
- 영속성을 예로 들면, 프로그래머는 영속성으로 저장할 객체와 속성을 선언한 후 영속성 책임을 영속성 프레임워크에게 위임한다. 그러면 AOP 프레임워크는 대상 코드에 영향을 미치지 않는 상태로 동작 방식을 변경한다.
자바 프록시
- 단순한 상황에 적합하다.
- 개별 객체나 클래스에서 메서드 호출을 감싸는 경우가 좋은 예다.
- 하지만 JDK에서 제공하는 동적 프록시는 인터페이스만 지원한다. (클래스 프록시 지원을 원하면 CGLIB, ASM, Javassit 와 같은 외부 바이트 코드 처리 라이브러리 사용)
- 목록 11-3 JDK 프록시 예제 참고
순수 자바 AOP 프레임워크
- 순수 자바 관점을 구현하는 Spring AOP 등과 같은 여러 자바 프레임워크는 내부적으로 프록시를 사용한다. (대부분의 프록시 코드는 판박이라 도구로 자동화 가능하다.)
- Spring은 비즈니스 논리를 POJO로 구현했다.
- POJO는 순수하게 도메인에 초점을 맞추어 다른 프레임워크에 의존하지 않아 테스트하기 쉽고 간단하다.
- 아래 예제 코드는 스프링 관련 자바 코드가 거의 필요 없으므로 애플리케이션은 사실상 스프링과 독립적이다. 즉, EJB2 시스템이 지녔던 강결합이라는 문제가 모두 사라진다.
1
2
| XmlBeanFactory bf = new XmlBeanFactory(new ClassPathResource("app.xml", getClass()));
Bank bank = (Bank) bf.getBean("bank");
|
AspectJ 관점
- 관심사를 관점으로 분리하는 가장 강력한 도구는 AspectJ 언어다.
- AspectJ는 언어 차원에서 관점을 모듈화 구성으로 지원하는 자바 언어 확장이다.
테스트 주도 시스템 아키텍처 구축
- 코드 수준에서 아키텍처 관심사를 구분할 수 있다면, 진정한 테스트 주도 아키텍처 구축이 가능하다.
- 최선의 시스템 구조는 각기 POJO (또는 다른) 객체로 구현되는 모듈화된 관심사 영역(도메인)으로 구성된다. 이렇게 서로 다른 영역은 해당 영역 코드에 최소한의 영향을 미치는 관점이나 유사한 도구를 사용해 통합한다. 이런 구조 역시 코드와 마찬가지로 테스트 주도 기법을 적용할 수 있다.
의사 결정을 최적화하라
- 우리는 때때로 가능한 마지막 순간까지 결정을 미루는 방법이 최선이라는 사실을 까먹곤 한다.
- 최대한 정보를 모아 최선의 결정을 내리기 위해서다.
- 성급한 결정은 불충분한 지식으로 내린 결정이다. 너무 일찍 결정하면 고객 피드백을 더 모으고, 프로젝트를 더 고민하고, 구현 방안을 더 탐험할 기회가 사라진다.
명백한 가치가 있을때 표준을 현명하게 사용하라
- 표준을 사용하면 아이디어와 컴포넌트를 재사용하기 쉽고, 적절한 경험을 가진 사람을 구하기 쉬우며, 좋은 아이디어를 캡슐화 하기 쉽고, 컴포넌트를 엮기 쉽다.
- 하지만 때로는 표준을 만드는 시간이 너무 오래 걸려 업계가 기다리지 못한다. 어떤 표준은 원래 표준을 제정한 목적을 잊어버리기도 한다.
- 여러 형태로 아주 과장되게 포장된 표준에 집착하는 바람에 고객 가치가 뒤전으로 밀려나도록 하지말자.
시스템은 도메인 특화 언어(DSL)가 필요하다.
- DSL은 간단한 스크립트 언어나 표준 언어로 구현한 API를 가리킨다. DSL로 짠 코드는 도메인 전문가가 작성한 구조적인 산문처럼 읽힌다.
- 좋은 DSL은 도메인 개념과 그 개념을 구현한 코드 사이에 존재하는 ‘의사소통 간극’을 줄여준다.
- 도메인 전문가가 사용하는 언어로 도메인 논리를 구현하면 도메인을 잘못 구현할 가능성이 줄어든다.
- 효과적으로 사용한다면 DSL은 추상화 수준을 코드 관용구나 디자인 패턴 이상으로 끌어올린다. 그래서 개발자가 적절한 추상화 수준에서 코드 의도를 표현할 수 있다.
도메인 특화 언어(Domain-Specific Language, DSL)를 사용하면 고차원 정책에서 저차원 세부사항에 이르기까지 모든 추상화 수준과 모든 도메인을 POJO로 표현할 수 있다.
결론
- 시스템 역시 깨끗해야 한다. 깨끗하지 못한 시스템 아키텍처는 도메인 논리를 흐리며 기민성을 떨어뜨린다. 도메인 논리가 흐려지면 제품 품질이 떨어진다. 버그가 숨어들기 쉬워지고, 스토리를 구현하기 어려워지는 탓이다. 기민성이 떨어지면 생산성이 낮아져 TDD가 제공하는 장점이 사라진다.
- 모든 추상화 단계에서 의도는 명확히 표현해야 한다. 그러려면 POJO를 작성하고 관점 혹은 관점과 유사한 메커니즘을 사용해 각 구현 관심사를 분리해야 한다.
- 시스템을 설계하든 개별 모듈을 설계하든, 실제로 돌아가는 가장 단순한 수단을 사용해야 한다는 사실을 명심하자.
Reference
Chapter12-창발성
창발적 설계로 깔끔한 코드를 구현하자
다음 켄트 벡이 제시한 단순한 설계 규칙 네 가지가 소프트웨어 설계 품질을 크게 높여준다고 믿는다.
1) 모든 테스트를 실행한다. 2) 중복을 없앤다. 3) 프로그래머 의도를 표현한다. 4) 클래스와 메서드 수를 최소로 줄인다.
단순한 설계 규칙1: 모든 테스트를 실행하라
- 테스트가 가능한 시스템을 만들려고 애쓰면 설계 품질이 더불어 높아진다. 크키가 작고 목적 하나만 수행하는 클래스가 나온다.
- 결합도가 높으면 테스트 케이스 작성하기 어려워진다. 그러므로 테스트 케이스를 많이 작성할수록 개발자는 DIP와 같은 원칙을 적용하고 DI, 인터페이스, 추상화 등과 같은 도구를 사용해 결합도를 낮춘다. 따라서 설계 품질은 더욱 높아진다.
단순한 설계 규칙 2~4: 리팩터링
- 위에서 테스트 케이스를 작성했다면 코드를 정리(리팩터링)하면서 시스템이 깨질 걱정이 사라진다.
- 리팩터링 단계에선 설계 품질을 높이는 기법이라면 무엇이든 적용해도 괜찮다.
- 응집도 높이고, 결합도 낮추고, 관심사 분리하고, 시스템 관심사를 모듈로 나누고, 함수와 클래스 크기를 줄이고, 더 나은 이름을 선택하는 등
- 또한 이 단계는 단순한 설계 규칙 중 나머지 3개를 적용해 중복을 제거하고, 프로그래머 의도를 표현하고, 클래스와 메서드 수를 최소로 줄이는 단계이기도 하다.
중복을 없애라
- 중복은 커다란 적이다. 추가 작업, 추가 위험, 불필요한 복잡도를 뜻하기 때문이다.
- 구현 중복도 중복의 한 형태다. 아래는 그 예제다.
1
2
| int size() {}
boolean isEmpty() {}
|
- 각 메서드를 따로 구현하는 방법도 있지만, isEmpty 메서드는 부울 값을 반환하며 size 메서드는 개수를 반환한다. 하지만 isEmpty 메서드에서 size 메서드를 이용하면 코드를 중복해 구현할 필요가 없어진다.
1
2
3
| boolean isEmpty() {
return 0 == size();
}
|
- 깔끔한 시스템을 만들려면 단 몇 줄이라도 중복을 제거하겠다는 의지가 필요하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public void scaleToOneDimension(float desiredDimension, float imageDimension) {
if (Math.abs(desiredDimension - imageDimension) < errorThreshold)
return;
float scalingFactor = desiredDimension / imageDimension;
scalingFactor = (float)(Math.floor(scalingFactor * 100) * 0.01f);
RenderedOpnewImage = ImageUtilities.getScaledImage(image, scalingFactor, scalingFactor);
image.dispose();
System.gc();
image = newImage;
}
public synchronized void rotate(int degrees) {
RenderedOpnewImage = ImageUtilities.getRotatedImage(image, degrees);
image.dispose();
System.gc();
image = newImage;
}
|
- scaleTOOneDimension 메서드와 rotate 메서드를 살펴보면 일부 코드가 동일하다. 다음과 같이 코드를 정리해 중복을 제거한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public void scaleToOneDimension(float desiredDimension, float imageDimension) {
if (Math.abs(desiredDimension - imageDimension) < errorThreshold)
return;
float scalingFactor = desiredDimension / imageDimension;
scalingFactor = (float) Math.floor(scalingFactor * 10) * 0.01f);
replaceImage(ImageUtilities.getScaledImage(image, scalingFactor, scalingFactor));
}
public synchronized void rotate(int degrees) {
replaceImage(ImageUtilities.getRotatedImage(image, degrees));
}
private void replaceImage(RenderedOpnewImage) {
image.dispose();
System.gc();
image = newImage;
}
|
- 아주 적은 양이지만 공통적인 코드를 새 메서드로 뽑고 보니 클래스가 SRP를 위반한다. 그러므로 새로 만든 replaceImage 메서드를 다른 클래스로 옮겨도 좋겠다. 그러면 새 메서드의 가시성이 높아진다. 따라서 다른 팀원이 이런 새 메서드를 좀 더 추상화해 다른 맥락에서 재사용 기회를 포착할지도 모른다.
- 이런 ‘소규모 재사용’은 시스템 복잡도를 극적으로 줄여준다. 소규모 재사용을 제대로 익혀야 대규모 재사용이 가능하다.
- 템플릿 메서드 패턴은 고차원 중복을 제거할 목적으로 자주 사용하는 기법이다.(예제 참고)
표현하라
- 대다수는 엉망인 코드를 접한 경험이 있다. 자신이 이해하는 코드를 짜기 쉽다. 하지만 나중에 코드를 유지보수할 사람이 코드를 짜는 사람만큼이나 문제를 깊이 이해할 가능성은 희박하다.
- 대다수 소프트웨어 프로젝트는 장기적인 유지보수에 들어간다. 코드를 변경하면서 버그의 싹을 ㅅ미지 않으려면 유지보수 개발자가 시스템을 제대로 이해해야 한다. 하지만 시스템이 점차 복잡해지면서 유지보수 개발자가 시스템을 이해하느라 보내는 시간은 점점 늘어나고 동시에 코드를 오해할 가능성도 점점 커진다.
- 그러므로 코드는 개발자의 의도를 분명히 표현해야 한다. (주석을 활용해서라도..) 그럴수록 다른 사람이 이해하기 쉬워지고 결함이 줄고 유지보수 비용이 적게 든다.
- 우선, 좋은 이름을 선택한다.
- 둘째, 함수와 클래스 크기를 가능한 줄인다. 작은 클래스와 함수는 명명도 쉽고, 구현하기도 쉽고, 이해하기도 쉽다.
- 셋째, 표준 명칭을 사용한다. 예를 들어, 디자인 패턴은 의사소통과 표현력 강화가 주요 목적이다. 클래스가 COMMAND나 VISITOR와 같은 표준 패턴을 사용해 구현된다면 클래스 이름에 패턴 이름을 넣어준다. 그러면 다른 개발자가 클래스 설계 의도를 이해하기 쉬워진다.
- 넷째, 단위 테스트 케이스를 꼼꼼히 작성한다. 잘 만든 테스트 케이스를 읽어보면 클래스 기능이 하눈에 들어온다.
- 하지만 표현력을 높이는 가장 중요한 방법은 노력이다. 흔히 코드만 돌린 후 다음 문제로 직행하는 사례가 너무 흔하다. 나중에 읽을 사람을 고려해 조금이라도 읽기 쉽게 만들려는 충분한 고민은 거의 찾기 어렵다. 하지만 나중에 코드를 읽을 사람은 바로 자신일 가능성이 높다는 사실을 명심하자.
- 그러므로 코드를 돌린후 함수와 클래스에 조금 더 시간을 투자하여 더 나은 이름을 선택하고, 큰 함수를 작은 함수로 쪼개는 등 자신의 작품에 조금만 더 주의를 기울이자. 주의는 대단한 재능이다.
클래스와 메서드 수를 최소로 줄여라
- 중복을 제거하고, 의도를 표현하고, SRP 를 준수한다는 기본적인 개념도 극단으로 치달으면 득보단 실이 많아진다. 클래스와 메서드 크기를 줄이자고 조그만 클래스와 메서드를 수없이 만드는 사례도 없지 않다.
- 때론 무의미하고 독단적인 정책 탓에 클래스 수와 메서드 수가 늘어나기도 한다.
- 클래스마다 무조건 인터페이스를 생성하라고 요구하는 구현 표준이 좋은 예다.
- 자료 클래스와 동작 클래스는 무조건 분리해야 한다고 주장하는 개발자도 좋은 예다.
- 가능한 독단적인 견해는 멀리하고 실용적인 방식을 택한다.
- 목표는 함수와 클래스 크기를 작게 유지하면서 동시에 시스템 크기도 작게 유지하는데 있다. 하지만 이 규칙은 간단한 설계 규칙 네가지중 우선순위가 가장 낮다. 다시 말해, 클래스와 함수 수를 줄이는 작업도 중요하지만, 테스트 케이스를 만들고 중복을 제거하고 의도를 표현하는 작업이 더 중요하다는 뜻이다.
Reference
Chapter13-동시성
동시성이 필요한 이유?
- 동시성은 결합(coupling)을 없애는 전략이다. 즉, 무엇(what)과 언제(when)을 분리하는 전략이다.
- 무엇과 언제를 분리하면 애플리케이션 구조와 효율이 극적으로 나아진다.
- 예를 들어, 서블릿은 웹 요청이 들어올때마다 웹서버는 비동기식으로 서블릿을 실행한다.
- 서블릿 프로그래머는 들어오는 모든 웹 요청을 관리할 필요가 없다.
- 원칙적으로 각 서블릿 스레드는 다른 서블릿 스레드와 무관하게 자신만의 세상에서 돌아간다.
- 어떤 시스템은 응답 시간과 작업 처리량 개선이라는 요구사항으로 인해 직접적인 동시성 구현이 불가피하다.
- 예를 들어, 매일 수 많은 웹 사이트에서 정보를 가져와 요약하는 정보 수집기(information aggregator), 정보를 대량으로 분석하는 시스템
미신과 오해
동시성과 관련한 일반적인 미신과 오해
- 동시성은 항상 성능을 높여준다.
- 때로는 성능을 높여준다. 여러 프로세서가 동시에 처리할 독립적인 계산이 충분히 많은 경우에만 성능이 높아진다.
- 동시성을 구현해도 설계는 변하지 않는다.
- 단일 스레드 시스템과 다중 스레드 시스템은 설계가 판이하게 다르다. 일반적으로 무엇과 언제를 분리하면 시스템 구조가 크게 달라진다.
- 웹 또는 EJB컨테이너를 사용하면 동시성을 이해할 필요가 없다.
- 실제로는 컨테이너가 어떻게 동작하는지, 어떻게 동시 수정, 데드락 등과 같은 문제를 피할 수 있는지를 알아야 한다.
동시성과 관련된 타당한 생각
- 동시성은 다소 부하를 유발한다. 성능 측면에서 부하가 걸리며, 코드도 더 짜야한다.
- 동시성은 복잡하다.
- 일반적으로 동시성 버그는 재현하기 어렵다.
- 동시성을 구현하려면 흔히 근본적인 설계 전략을 재고해야 한다.
동시성 방어 원칙
- 동시성 코드가 일으키는 문제로부터 시스템을 방어하는 원칙과 기술을 소개한다.
단일 책임 원칙 (Single Responsibility Principle, SRP)
- 주어진 메서드/클래스/컴포넌트를 변경할 이유가 하나여야 한다는 원칙이다.
- 동시성은 복잡성 하나만으로도 분리할 이유가 충분하다.
- 권장사항: 동시성 관련 코드는 다른 코드와 분리해야 한다.
따름 정리(corollary): 자료 범위를 제한하라
- 공유 객체를 가용하는 코드 내 임계영역(critical section)을 synchronized 키워드로 보호하라고 권장한다.
- 이런 임계영역의 수를 줄이는 기술이 중요하다. 공유 자료를 수정하는 위치가 많을수록 다음 가능성도 커진다.
- 보호할 임계영역을 빼먹는다. 그래서 공유 자료를 수정하는 모든 코드를 망가뜨린다.
- 모든 임계영역을 올바로 보호했는지 확인하느라 똑같은 노력과 수고를 반복한다.
- 그렇지 않아도 찾아내기 어려운 버그가 더욱 찾기 어려워진다.
- 권장사항: 자료를 캡슐화하라. 공유 자료를 최대한 줄여라.
따름 정리(corollary): 자료 사본을 사용하라
- 공유 자료를 줄이려면 처음부터 공유하지 않는 방법이 제일 좋다.
- 어떤 경우에는 객체를 복사해 읽기 전용으로 사용하는 방법이 가능하며, 어떤 경우에는 각 스레드가 객체를 복사해 사용후 한 스레드가 해당 사본에서 결과를 가져오는 방법도 가능하다.
따름 정리(corollary): 스레드는 가능한 독립적으로 구현하라
- 자신만의 세상에 존재하는 스레드를 구현하라. 즉, 다른 스레드와 자료를 공유하지 않도록 말이다.
- 예를 들어, HttpServlet 클래스에서 파생한 클래스는 모든 정보를 doGet 과 doPost 매개변수로 받는다. 그래서 각 서블릿은 마치 자신이 독자적인 시스템에서 동작하는 양 요청을 처리한다. 서블릿 코드가 로컬 변수만 사용한다면 서블릿이 동기화 문제를 일으킬 가능성은 전무하다. 물론 서블릿을 사용하는 대다수 애플리케이션은 결국 DB 커넥션과 같은 자원을 공유하는 상황에 처한다.
- 권장사항: 독자적인 스레드로, 가능하면 다른 프로세서에서 돌려도 괜찮도록 자료를 독립적인 단위로 분할하라.
라이브러리를 이해하라
- 자바5는 동시성 측면에서 이전 버전보다 많이 나아졌다.
- 스레드 환경에 안전한 컬렉션을 사용한다. 자바5부터 제공한다.
- 서로 무관한 작업을 수행할때는 executor 프레임워크를 사용한다.
- 가능하다면 스레드가 차단(blocking)되지 않는 방법을 사용한다.
- 일부 클래스 라이브러리는 스레드에 안전하지 못하다.
스레드 환경에 안전한 컬렉션
- java.util.concurrent 패키지가 제공하는 클래스는 다중 스레드 환경에서 사용해도 안전하며, 성능도 좋다.
- 실제로 ConcurrentHashMap은 거의 모든 상황에서 HashMap 보다 빠르다. 동시 읽기/쓰기를 지원하며 자주 사용하는 복합 연산을 다중 스레드 상에서 안전하게 만든 메서드로 제공한다.
- 자바 5이상을 사용한다면 ConcurrentHashMap부터 살펴봐라.
- 그외적으론 java.util.concurrent.atomic, java.util.concurrent.lock를 익혀라
실행 모델을 이해하라
- 먼저 아래 용어들을 익혀라.
- 한정된 자원(Bound Resource): 다중 스레드 환경에서 사용하는 자원으로, 크기나 숫자가 제한적이다. DB 커넥션, 길이가 일정한 읽기/쓰기 등이 예다.
- 상호 배제(Mutual Exclusion): 한 번에 한 스레드만 공유 자료나 공유 자원을 사용할 수 있는 경우를 가리킨다.
- 기아(Starvation): 한 스레드나 여러 스레드가 굉장히 오랫동안 혹은 영원히 자원ㅇ늘 기다린다. 예를 들어, 항상 짧은 스레드에게 우선순위를 준다면, 짧은 스레드가 지속적으로 이어질 경우, 긴 스레드가 기아 상태에 빠진다.
- 데드락(Deadlock): 여러 스레드가 서로가 끝나기를 기다린다. 모든 스레드가 각기 필요한 자원을 다른 스레드가 점유하는 바람에 어느 쪽도 더 이상 진행하지 못한다.
- 라이브락(Livelock): 락을 거는 단계에서 각 스레드가 서로를 방해한다. 스레드는 계속해서 진행하려 하지만, 공명(resonance)으로 인해, 굉장히 오랫동안 혹은 영원히 진행하지 못한다.
- 다중 스레드 프로그래밍에서 사용하는 실행 모델을 몇 가지 살펴바.
생산자-소비자(Producer-Consumer)
읽기/쓰기(Readers-Writers)
- 쓰기 스레드가 버퍼를 갱신하는 동안 읽기 스레드가 버퍼를 읽지 않으려면, 마찬가지로 읽기 스레드가 버퍼를 읽는 동안 쓰기 스레드가 버퍼를 갱신하지 않으려면, 복잡한 균형잡기가 필요하다. 대개는 쓰기 스레드가 버퍼를 오랫동안 점유하는 바람에 여러 읽기 스레드가 버퍼를 기다리느라 처리율이 떨어진다.
- 따라서 읽기 스레드의 요구와 쓰기 스레드의 요구를 적절히 만족시켜 처리율도 적당히 높이고 기아도 방지하는 해법이 필요하다. 간단한 전략은 읽기 스레드가 없을때까지 갱신을 원하는 쓰기 스레드가 버퍼를 기다리는 방법이다.
식사하는 철학자들
- 기업 애플리케이션은 여러 프로세스가 자원을 얻으려 경쟁한다. 주의해서 설계하지 않으면 데드락, 라이브락, 처리율 저하, 효율성 저하 등을 겪는다.
- 일상에서 접하는 대다수 다중 스레드 문제는 (형태가 조금씩 다를지라도) 위 세 범주중 하나에 속한다. 각 알고리즘을 공부하고 해법을 직접 구현해보라. 그러면 나중에 실전 문제에 부닥쳤을 때 해결이 쉬워질것이다.
동기화하는 메서드 사이에 존재하는 의존성을 이해하라
- 공유 객체 하나에는 메서드 하나만 사용하라.
- 단 공유 객체 하나에 여러 메서드가 필요한 상황도 생긴다. 그럴땐 다음 세 가지 방법(p.236)을 고려한다.
동기화하는 부분을 작게 만들어라
- 자바에선 synchronized 키워드를 사용하면 락을 설정한다. 같은 락으로 감싼 모든 코드 영역은 한 번에 한 스레드만 실행이 가능하다.
- 락은 스레드를 지연시키고 부하를 가중시킨다. 그러므로 여기저기서 synchronized 문을 남발하는 코드는 바람직하지 않다.
- 반면, 임계 영역(critical section)은 반드시 보호해야 한다. 따라서 코드를 짤 때는 임계영역 수를 최대한 줄여야 한다.
- 임계영역 수를 줄인답시고 거대한 임계영역 하나로 구현하지 말자. 필요 이상으로 임계영역 크기를 키우면 스레드 간에 경쟁이 늘어나고 프로그램 성능이 저하된다.
올바른 종료 코드는 구현하기 어렵다.
- 가장 흔히 발생하는 문제는 데드락이다. 즉, 스레드가 절대 오지 않을 시그널을 기다린다.
스레드 코드 테스트하기
- 문제를 노출하는 테스트 케이스를 작성하고 프로그램 설정과 시스템 설정과 부하를 바꿔가며 자주 돌려라. 일회성 실패도 그냥 넘어가선 안된다.
- 고려할 사항들을 살펴보자.
- 말이 안되는 실패는 잠정적인 스레드 문제로 취급하라.
- 다중 스레드를 고려하지 않은 순차 코드부터 제대로 돌게 만들자.
- 다중 스레드를 쓰는 코드 부분을 다양한 환경에 쉽게 끼워 넣을수 있도록 스레드 코드를 구현하라.
- 다중 스레드를 쓰는 코드 부분을 상황에 맞춰 조정할 수 있게 작성하라.
- 스로세서 수보다 많은 스레드를 돌려보라.
- 다른 플랫폼에서 돌려보라.
- 코드에 보조 코드(instrument)를 넣어 돌려라. 강제로 실패를 일으키게 해보라.
말이 안되는 실패는 잠정적인 스레드 문제로 취급하라
- 시스템 실패를 ‘일회성’이라 치부하지 마라.
- 스레드 환경 밖에서 생기는 버그와 스레드 환경에서 생기는 버그를 동시에 디버깅하지 마라. 먼저 스레드 환경 밖에서 코드를 올바로 돌려라.
다중 스레들르 쓰는 코드 부분을 다양한 환경에 쉽게 끼워 넣을 수 있게 스레드 코드를 구현하라
- 한 스레드로 실행하거나, 여러 스레드로 실행하거나, 실행 중 스레드 수를 바꿔본다.
- 스레드 코드를 실제 환경이나 테스트 환경에서 돌려본다.
- 테스트 코드를 빨리, 천천히, 다양한 속도로 돌려본다.
- 반복 테스트가 가능하도록 테스트 케이스를 작성한다.
다중 스레드를 쓰는 코드 부분을 상황에 맞게 조율할 수 있게 작성하라
- 스레드 개수를 조율하기 쉽게 코드를 구현한다.
- 프로그램이 돌아가는 도중에 스레드 개수를 변경하는 방법도 고려한다.
- 프로그램 처리율과 효율에 따라 스스로 스레드 개수를 조율하는 코드도 고민한다.
프로세서 수보다 많은 스레드를 돌려보라
- 시스템이 스레드를 스와핑(swapping)할때도 문제가 발생한다. 스와핑을 일으키려면 프로세서 수보다 많은 스레드를 돌린다. 스와핑이 잦을수록 임계영역을 빼먹은 코드나 데드락을 일으키는 코드를 찾기 쉬워진다.
다른 플랫폼에서 돌려보라
- linux, window 등 여러 환경에서 돌려라.
- 운영체제마다 스레드 처리 정책이 달라 결과가 달라질 수 있다.
- 다중 스레드 코드는 플랫폼에 따라 다르게 돌아간다. 따라서 코드가 돌아갈 가능성이 잇는 플랫폼 전부에서 테스트를 수행해야 마땅하다.
코드에 보조 코드를 넣어 돌려라. 강제로 실패를 일으키게 해보라
- 스레드 코드는 오류를 찾기가 쉽지 앟ㄴ다.
- 드물게 발생하는 스레드 버그를 좀 더 자주 일으킬 방법은 없을까? 보조 코드를 추가해 코드가 실행되는 순서를 바꿔준다.
- 예를 들어, Object.wait(), Object.sleep(), Object.yield(), Object.priority() 등과 같은 메서드를 추가해 코드를 다양한 순서로 실행한다.
- 각 메서드는 스레드가 실행되는 순서에 영향을 미친다. 따라서 버그가 드러날 가능성도 높아진다. 잘 못된 코드라면 가능한 초반에 그리고 가능한 자주 실패하는 편이 좋다.
- 코드에 보조 코드를 추가하는 방법은 두 가지다.
- 1)직접 구현 - 소스 코드에 직접 wait(), sleep(), yield(), priority() 함수를 추가한다. 특별히 까다로운 코드를 테스트시 적합gkek.
- 2)자동화 - 보조 코드를 자동으로 추가하려면 AOF, CGLIB, ASM 등과 같은 도구를 사용한다.
결론
- 다중 스레드 코드는 올바로 구현하기 어렵다.
- 다중 스레드 코드를 작성한다면 각별히 깨끗하게 코드를 짜야 한다.
- SRP를 준수하고, POJO를 사용해 스레드를 아는 코드와 모르는 코드를 분리하고, 테스트는 스레드만 테스트하여 스레드 코드를 최대한 집약되고 작게 만들어야 한다.
- 동시성 오류를 일으키는 잠정적인 원인을 철저히 이해해야 한다. 예를 들어, 여러 스레드가 공유 자료를 조작하거나 자원 풀을 공유할 때 동시성 오류가 발생한다. 루프 반복을 끝내거나 프로그램을 깔끔하게 종료하는 등 경계 조건의 경우가 까다로우므로 특히 주의한다.
- 사용하는 라이브러리와 기본 알고리즘을 이해한다.
- 공유하는 정보와 공유하지 않는 정보를 제대로 이해해야 한다. 그리고 아래 내용을 숙지해야 한다.
- 잠글 필요가 없는 코드는 잠그지 않는다.
- 잠긴 영역에서 다른 잠긴 영역을 호출하지 않는다.
- 공유하는 객체 수와 범위를 최대한 줄인다.
- 여러 테스트를 통해 동시성 오류를 일으키는 잠정적인 원인을 철저히 이해해야 한다. (출시하기 전까지 최대한 오랫동안 돌려보아야 한다.)
- 많은 플랫폼에서 많은 설정으로 반복해서 계속 테스트해야 한다.
- 시간을 들여 보조 코드를 추가하면 오류가 드러날 가능성이 크게 높아진다.
- 직접 구현해도 괜찮고 몇 가지 자동화 기술을 사용해도 괜찮다.
- 깔끔한 접근 방식을 취한다면 코드가 올바로 돌아갈 가능성이 극적으로 높아진다.
Reference
Chapter14-점진적인 개선
- 이 장은 점진적인 개선을 보여주는 사례다. 프로그램을 짜다보면 종종 명령행 인수(
public static void main(String[] args))의 구문을 분석할 필요가 있는데 이 구문을 분석할 유틸리티 모듈을 개선해나가는 예제를 설명한다. - 세부적인 개선 과정과 자세한 내용은 서적을 참고하기 바란다. p.246
결론
- 깨끗한 코드를 짜려면 먼저 지저분한 코드를 짠 뒤에 정리해야 한다.
- 오래된 의존성을 찾아내 깨려면 상당한 시간과 인내심이 필요하다.
- 반면 처음부터 코드를 깨끗하게 유지하기란 상대적으로 쉽다. 아침에 엉망으로 만든 코드를 오후에 정리하기는 어렵지 않다. 더욱이 5분 전에 엉망으로 만든 코드는 지금 당장 정리하기 아주 쉽다.
- 그러므로 코드는 언제나 최대한 깔끔하고 단순하게 정리하자. 절대로 썩어가게 방치하면 안된다.
Reference
Chapter15-Junit 들여다보기
- Junit 은 자바 프레임워크 중에서 가장 유명하다.
- 일반적인 프레임워크가 그렇듯 개념은 단순하며 정의는 정밀하고 구현은 우아하다.
- 하지만 실제 코드는 어떨까? 이 장에서는 Junit 프레임워크에서 가져온 코드를 평가한다.
Junit 프레임워크
- Junit 은 저자가 많다. 하지만 시작은 켄트 벡과 에릭 감마, 두 사람이 함께 아틀란타행 비행기를 타고 가다 Junit을 만들었다.
- Junit 내부의 문자열 비교 오류를 파악할 때 유용한 코드인 ComparisonCompactor 라는 모듈을 살펴볼 예정인데 자세한 내용은 서적을 참고바란다.(p.324)
결론
- 코드를 처음보다 조금 더 깨끗하게 만드는 책임은 우리 모두에게 있다.
Reference
Chapter16-SerialDate 리팩터링
- 일반적으로 기반 클래스 (base class, 부모 클래스)는 파생 클래스(derivative, 자식 클래스)를 몰라야 바람직하다. (p.351)
- 저자는 실질적인 가치가 없으면서 코드만 복잡하게 만드는 인수와 변수 선언된 final 키워드를 제거하는게 좋다고 한다. (p.356)
- final을 제거하는것은 일부 기존 관례에 어긋난다. 예를 들어, 로버트 시몬스는 “코드 전체에 final을 사용하라…“고 강력히 권장한다.
- 저자는 final 키워드는 final 상수 등 몇 군데를 제외하면 별다른 가치가 없으며 코드만 복잡하게 만든다고 한다.
- 어쩌만 저자가 만든 테스트 케이스가 final 키워드로 잡아낼 오류를 모두 잡아내기 때문일지도 모른다고 한다.
- 일반적으로 메서드 인수로 플래그는 바람직하지 못하다. 특히 출력 형식을 선택하는 플래그는 가급적 피하는 편이 좋다.(p. 358)
- addDays 메서드는 온갖 DayDate 변수를 사용하므로 static 이어선 안된다. 그래서 인스턴스 변수로 변경하는게 좋다.(p. 360)
- addDays 메서드를 정적 메서드에서 인스턴스 메서드로 바꾸면서 뭔가 꺼림칙했다. date.addDays(5)라는 표현이 date 객체를 변경하지 않고 새 DayDate 인스턴스를 반환한다는 사실이 분명하게 드러나지 않기 떄문이다.(p.360)
- 그래서 저자는 메서드의 원래 의도를 잘 반영하는 네이밍인 plusDays와 plusMonths라는 이름을 선택했다. 개인적으론 크게 공감되진 않는다….ㅎㅎ
1
| DayDate date = oldDate.plusDays(5);
|
Reference
Chapter17-냄새와 휴리스틱
주석
C1: 부적절한 정보
- 다른 시스템(ex. 소스 코드 관리 시스템, 이슈 추적 시스템 등)에 저장할 정보는 주석으로 적절치 못하다.
- 예를 들어, 변경 이력은 장황한 날짜와 따분한 내용으로 소스 코드만 번잡하게 만든다.
- 주석은 코드와 설계에 기술적인 설명을 부연하는 수단이다.
C2: 쓸모 없는 주석
- 오래된, 엉뚱한, 잘못된 주석은 더 이상 쓸모가 없다.
- 쓸모 없어질 주석은 아예 달지 않는 편이 가장 좋다.
- 쓸모 없어진 주석은 재빨리 삭제하는 편이 가장 좋다.
- 쓸모 없는 주석은 일단 들어가고 나면 코드에서 쉽게 멀어진다.
- 코드와 무관하게 혼자서 따로 놀며 코드를 그릇된 방향으로 이끈다.
C3: 중복된 주석
- 코드만으로 충분한데 구구절절 설명하는 주석이 중복된 주석이다.
C4: 성의 없는 주석
- 주석을 달 참이라면 시간을 들여 최대한 멋지게 작성한다. 단어를 신중히 선택한다.
- 주절대지 않는다. 당연한 소리를 반복하지 않는다. 간결하고 명료하게 작성한다.
C5: 주석 처리된 코드
- 읽는 사람을 헷갈리게 만든다. 흉물 그 자체다. 즉각 지워버려라!
- 걱정할 필요 없다. 소스 코드 관리 시스템이 기억하니깐 누군가 정말로 필요하면 이전 버전을 가져올것이다.
환경
E1: 여러 단계로 빌드해야 한다.
- 빌드는 간단히 한 단계로 끝나야 한다. 소스 코드 관리 시스템에서 이것저것 따로따로 체크아웃할 필요가 없어야 한다.
E2: 여러 단계로 테스트해야 한다.
- 모든 테스트를 한 번에 실행하는 능력은 아주 근본적이고 아주 중요하다.
- 따라서 그 방법이 빠르고, 쉽고, 명백해야 한다.
함수
F1: 너무 많은 인수
- 함수에서 인수 개수는 적을수록 좋다. 아예 없으면 가장 좋다. 다음으로 하나, 둘, 셋이 좋다.
- 넷 이상은 그 가치가 아주 의심스러우므로 최대한 피한다. (50쪽 “함수 인수” 참조)
F2: 출력 인수
- 함수에서 뭔가의 상태를 변경해야 한다면 (출력 인수를 쓰지 말고) 함수가 속한 객체의 상태를 변경한다. (56쪽 “출력 인수” 참조)
F3: 플래그 인수
- boolean 인수는 함수가 여러 기능을 수행한다는 명백한 즈억다. 플래그 인수는 혼란을 초래하므로 피해야 마땅하다. (52쪽 “플래그 인수” 참조)
F4: 죽은 함수
- 아무도 호출하지 않는 함수는 삭제한다. 죽은 코드는 낭비다.
- 소스 코드 관리 시스템이 모두 기억하므로 걱정할 필요 없다.
일반
G1: 한 소스 파일에 여러 언어를 사용한다
- 소스 파일 하나에 언어 하나만 사용하는 방식이 가장 좋다.
- 예를 들어, 어떤 JSP 파일은 HTML, 자바, 태그 라이브러리 구문, 영어 주석, Javadoc, XML, javascript 등을 포함한다..
- 각별한 노력을 기울여 소스 파일에서 언어 수와 범위를 최대한 줄이도록 애써야 한다.
G2: 당연한 동작을 구현하지 않는다
- 함수나 클래스는 다른 프로그래머가 당연하게 여길만한 동작과 기능을 제공해야 한다.
- 그렇지 않으면 코드를 읽거나 사용하는 사람이 더 이상 함수 이름만으로 함수 기능을 직관적으로 예상하기 어렵다.
- 저자를 신뢰하지 못하므로 코드를 일일이 살펴야 한다.
G3: 경계를 올바로 처리하지 않는다
- 로직에서 경계 부분을 항상 조심하고 신경써야한다.
- 모든 경계 조건을 찾아내고, 모든 경계 조건을 테스트하는 테스트 케이스를 작성하라.
G4: 안전 절차 무시
- 안전 절차를 무시하면 안된다.
- 실패하는 테스트 케이스를 일단 제껴두고 나중으로 미루는 태도는 신용카드가 공짜 돈이라는 생각만큼 위험하다.
G5: 중복
- 코드에서 중복을 발견할 때마다 추상화할 기회로 간주한다.
- 좀 더 미묘한 유형은 여러 모듈에서 일련의 switch/case 나 if/else 문으로 똑같은 조건을 거듭확인하는 중복이다. 이런 중복은 다형성(polymorphism)으로 대체해야 한다.
- 더더욱 미묘한 유형은 알고리즘이 유사하나 코드가 서로 다른 중복이다. TEMPLATE METHOD 패턴이나 STRATEGY 패턴으로 중복을 제거한다.
- 사실 최근 15년 동안 나온 디자인 패턴은 대다수가 중복을 제거하는 잘 알려진 방법에 불과하다.
- 어디서든 중복을 발견하면 없애라.
G6: 추상화 수준이 올바르지 못하다
- 추상화는 저차원 상세 개념에서 고차원 일반 개념을 분리한다.
- 세부 구현과 관련한 상수, 변수, 유틸리티 함수는 기초 클래스에 넣으면 안된다. 기초 클래스는 구현 정보에 무지해야 마땅하다.
- 소스 파일, 컴포넌트, 모듈도 마찬가지다. 우수한 소프트웨어 설계자는 개념을 다양한 차원으로 분리해 다른 컨테이너에 넣는다.
- 고차원 개념과 저차원 개념을 섞어서는 안된다.
1
2
3
4
5
6
7
| public interface Stack {
Object pop() throws EmptyException;
void push(Object o) throws FullException;
double percentFull();
class EmptyException extends Exception {}
class FullException extends Exception {}
}
|
- percentFull 함수는 추상화 수준이 올바르지 못하다. Stack을 구현하는 방법은 다양하다. 어떤 구현은 ‘꽉 찬 정도’라는 개념이 타당하지만 어떤 구현은 알아낼 방법이 전혀 없다. 그러므로 함수는 BoundedStack 과 같은 파생 인터페이스에 넣어야 마땅하다.
- 크기가 무한한 스택은 0을 반환하면 되지 않나? 라고 물을지도 모른다. 하지만 진정으로 무한한 스택은 존재하지 않는다. 다음 코드는 스택 크기를 확인했다는 이유만으로 OutOfMemoryException 예외가 절대 발생하지 않으리라 장담하지 못한다.
1
| stack.percentFull() < 50.0;
|
G7: 기초 클래스가 파생 클래스에 의존한다
- 기초 클래스는 파생 클래스를 아예 몰라야 한다.
- 물론 예외는 있다. 간혹 파생 클래스의 개수가 확실히 고정되었따면 기초 클래스에 파생 클래스를 선택하는 코드가 들어간다.
- 기초 클래스와 파생 클래스를 다른 JAR 파일로 배포하면, 그리고 기초 JAR 파일이 파생 JAR 파일을 전혀 모른다면, 독립적인 개별 컴포넌트 단위로 시스템을 배치할 수 있다. 그렇게 되면변경이 시스템에 미치는 영향이 아주 작아지므로 현장에서 시스템을 유지보수하기 한결 수월하게 된다.
G8: 과도한 정보
- 잘 정의된 모듈은 인터페이스가 아주 작다. 작은 인터페이스로도 많은 동작이 가능하다.
- 잘 정의된 인터페이스는 많은 함수를 제공하지 않는다. 그래서 결합도(coupling)가 낮다. 부실하게 정의된 인터페이스는 반드시 호출해야 하는 온갖 함수를 제공한다.그래서 결합도가 높다.
- 우수한 소프트웨어 개발자는 클래스나 모듈 인터페이스에 노출할 함수를 제한할줄 알아야 한다.
- 클래스가 제공하는 메서드 수는 작을수록 좋다. 함수가 아는 변수 수도 작을수록 좋다. 클래스에 들어 있는 인스턴스 변수 수도 작을수록 좋다.
- 자료를 숨겨라. 유틸리티 함수를 숨겨라. 상수와 임시 변수를 숨겨라. 메서드나 인스턴스 변수가 넘쳐나는 클래스는 피하라. 하위 클래스에서 필요하다는 이유로 protected 변수나 함수를 마구 생성하지 마라. 인터페이스를 매우 작게 그리고 매우 깐깐하게 만들어라. 정보를 제한해 결합도를 낮춰라.
G9: 죽은 코드
- 실행되지 않는 코드를 가리킨다.
- ex. 불가능한 조건을 확인하는 if문, throw문이 없는 try문에서의 catch 블록, 아무도 호출하지 않는 유틸리티 함수와 switch/case 문에서 불가능한 case 조건
- 죽은 코드는 시간이 지나면 악취를 풍기기 시작한다.
- 죽은지 오래될수록 악취는 강해진다. 죽은 코드는 설계가 변해도 제대로 수정되지 않기 때문이다. 컴파일은 되지만 새로운 규칙이나 표기법을 따르지 않는다.
- 적절한 장례식을 치뤄주라. 시스템에서 제거하라.
G10: 수직 분리
- 변수와 함수는 사용되는 위치에 가깝게 정의한다.
- 지역 변수는 처음으로 사용하기 직전에 선언하며 수직으로 가까운 곳에 위치해야 한다.
- 비공개 함수는 처음으로 호출한 직후에 정의한다. 비공개 함수는 전체 클래스 범위에 속하지만 그래도 정의하는 위치와 호출하는 위치를 가깝게 유지한다.
- 비공개 함수는 처음으로 호출되는 위치를 찾은후 조금 아래로 내려가면 쉽게 눈에 띄어야 한다.
G11: 일관성 부족
- 어떤 개념을 특정 방식으로 구현했다면 유사 개념도 같은 방식으로 구현한다.
- 한 함수에서 response 라는 변수에 HttpServletResponse 인스턴스를 저장했다면 다른 함수에서도 일관성 있게 동일한 변수명을 사용한다.
- 한 메서드를 processVerificationRequest 라 명명했다면 (유사한 요청을 처리하는) 다른 메서드도 (processDeletionRequest처럼) 유사한 이름을 사용한다.
- 이처럼 간단한 일관성만으로도 코드를 읽고 수정하기 대단히 쉬워진다.
G12: 잡동사니
- 비어있는 기본생성자, 미사용 변수, 미사용 함수, 정보를 제공하지 못하는 주석은 모두 코드만 복잡하게 만들 뿐이므로 제거해야 마땅하다.
- 소스 파일은 언제나 깔끔하게 정리하라! 잡동사니를 없애라!
G13: 인위적 결합
- 서로 무관한 개념을 인위적으로 결합하지 않는다.
- 예를 들어, 일반적인 enum 은 특정 클래스에 속할 이유가 없다. enum이 클래스에 속한다면 enum을 사용하는 코드가 특정 클래스를 알아야만 한다. 범용 static 함수도 마찬가지로 특정 클래스에 속할 이유가 없다.
- 뚜렷한 목적 없이 변수, 상수, 함수를 당장 편한 위치(물론 잘못된 위치)에 넣어버린 결과다. 게으르고 부주의한 행동이고 변수, 상수, 함수를 선언시엔 시간을 들여 올바른 위치를 고민한다.
G14: 기능 욕심
- 마틴 파울러가 말하는 코드 냄새중 하나다.
- 클래스 메서드는 자기 클래스의 변수와 함수에 관심을 가져야지 다른 클래스의 변수와 함수에 관심을 가져선 안된다.
- 메서드가 다른 객체의 참조자와 변경자를 사용해 그 객체 내용을 조작한다면 메서드가 그 객체 클래스의 범위를 욕심내는 탓이다.
- 자신이 그 클래스에 속해 그 클래스 변수를 직접 조작하고 싶다는 뜻이다.
- 아래 코드에서 calculateWeeklyPay 메서드는 HourlyEmployee 클래스의 범위를 욕심낸다. calculateWeeklyPay 메서드는 HourlyEmployee 객체에서 온갖 정보를 가져온다.
1
2
3
4
5
6
7
8
9
10
11
| public class HourlyPayCalculator {
public Money calculateWeeklyPay(HourlyEmployee e) {
int tenthRate = e.getTenthRate().getPennies();
int tenthsWorked = e.getTenthsWorked();
int straightTime = Math.min(400, tenthWorked);
int overTime = Math.max(0, tenthsWorked - straightTime);
int straightPay = straightTime * tenthRate;
int overtimePay = (int)Math.round(overTime * tenthRate * 1.5);
return new Money(straightPay + overtimePay);
}
}
|
- 기능 욕심은 한 클래스의 속사정을 다른 클래스에 노출하므로, 별다른 문제가 없다면 제거하는 편이 좋다.
- 하지만 때로는 어쩔 수 없는 경우도 생긴다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class HourlyEmployeeReport {
private HourlyEmployee employee;
public HourlyEmployeeReport(HourlyEmployee e) {
this.employee = e;
}
String reportHours() {
"Name : %s\tHours : %d.%1d\n",
employee.getName(),
employee.getTenthsWorked() / 10,
employee.getTenthsWorked() % 10);
}
}
|
- reportHours 메서드는 HourlyEmployee 클래스를 욕심낸다. 하지만 그렇다고 HourlyEmployee 클래스가 보고서 형식을 알 필요는 없다.(역할과 책임 관점에서)
- 함수를 HourlyEmployee 클래스로 옮기면 객체 지향 설계의 여러 원칙을 위반한다.
- HourlyEmployee가 보고서 형식과 결합되므로 보고서 형식이 바뀌면 해당 클래스도 바뀐다..
G15: 선택자 인수
- 선택자 인수(boolean)는 큰 함수를 작은 함수 여럿으로 쪼개지 않으려는 게으름의 소산이다. (p.379 예제 참고)
- enum, int 등 함수 동작을 제어하려는 인수는 하나 같이 바람직하지 않고 일반적으로 인수를 넘겨 동작을 선택하는 대신 새로운 함수를 만드는 편이 좋다.
G16: 모호한 의도
- 코드를 짤 때는 의도를 최대한 분명히 밝힌다.
- 행을 바꾸지 않고 표현한 수식, 헝가리식 표기법, 매직 번호 등은 모두 저자의 의도를 흐린다.
G17: 잘못 지운 책임
- 코드 설계 시 코드 배치 위치를 결정하는 것은 중요하다. 여기서 배치 위치는 독자가 여기있겠구나 싶은 곳에 배치하는것이 좋다.
- 때로는 독자에게 직관적인 위치가 아니라 개발자에게 편한 곳에 배치하기도 한다. 이때 결정을 내리는 기준 중 한가지는 함수의 이름을 살펴보는 것이다.
- 근무 시간 총계를 보고서로 출력하는 함수가 필요하다고 했을때, 보고서 모듈의 getTotalHours 함수와 근무시간을 입력받는 saveTimeCard 함수 중 어느쪽에서 계산하는 것이 맞을까? 전자다.
- 성능을 높이고자 근무시간을 입력 받는 곳에서 총계를 계산한다고 하면 computeRunningTotalOfHours 이라는 함수를 내부에 넣어주는것이 좋다.
G18: 부적절한 static 함수
- Math.max(double a, double b)는 좋은 static 메서드다. 특정 인스턴스와 관려된 기능이 아니기에 new Math().max(a, b)라 하면 오히려 우습다. 결정적으로 재정의할 가능성은 전혀 없다.
- 그런데 간혹 우리는 static 으로 정의하면 안되는 함수를 static 으로 정의한다.
- 아래와 같이 수당을 계산하는 함수인데 재정의할 가능성이 존재하기에 적절치 않다. (수당 계산 알고리즘은 여러개 일수있으니, 일반 수당 계산과 초과 근무 수당 계산)
1
| HourlyPayCalculator.calculatePay(employee, overtimeRate);
|
- 일반적으로 static 함수보다 인스턴스 함수가 더 좋다. 조금이라도 의심스럽다면 인스턴스 함수로 정의한다. 반드시 static 함수로 정의해야겠다면 재정의할 가능성은 없는지 꼼꼼히 따져본다.
G19: 서술적 변수
- 켄트 벡이 Smalltalk Best Practice Patterns 라는 훌륭한 책과 Implementation Patterns 라는 훌륭한 책에서 지적하는 문제다.
- 프로그램의 가독성을 높이는 가장 효과적인 방법 중 하나가 계산을 여러 단계로 나누고 중간 값으로 서술적인 변수 이름을 사용하는 방법이다.
1
2
3
4
5
6
7
| Matcher match = headerPattern.matcher(line);
if(match.find())
{
String key = match.group(1);
String value = match.group(2);
headers.put(key.toLowerCase(), value);
}
|
- 위 코드에서 서술적 변수 이름을 사용했기 때문에 첫번째로 일치하는 그룹이 key에 해당되며 두번째 그룹은 value라는 부분이 명백하게 드러난다.
- 서술적 변수명은 많이 써도 괜찮고, 일반적으로 많을수록 더 좋다.
G20: 이름과 기능이 일치하는 함수
1
| Date newDate = date.add(5);
|
- 위 함수를 보면 date.add가 의미하는 바가 날짜인지, 시간인지, 주인지 모호하다. 5일을 더해 date 인스턴스를 변경하는 함수라면 addDaysTo 혹인 increaseByDays라는 이름이 좋다.
- 이름만으로 분명하지 않기에 구현을 살피거나 문서를 뒤적여야 한다면 더 좋은 이름으로 바꾸거나 아니면 더 좋은 이름을 붙이기 쉽게 기능을 정리해야 한다.
G21: 알고리즘을 이해하라
- 코드가 단순히 돌아가여 테스트 코드를 통과한다고 끝나면 안된다.
- 함수가 동작하는 방식을 완전히 이해하는지 확인해야 한다.
- 이를 위해선 기능이 뻔히 보일 정도로 함수를 깔끔하고 명확하게 재구성하는 방법이 최고다.
G22: 논리적 의존성은 물리적으로 드러내라
- 한 모듈이 다른 모듈에 의존한다면 물리적 의존성도 있어야 한다. 물리적으로 의존하면 의존하는 정보를 명시적으로 요청하는 편이 좋다.
- 근무 시간 보고서를 가공되지 않은 상태로 출력하는 함수를 만든다고 할때 HourlyReporter 클래스는 정보를 모아 HourlyReportFormatter 클래스에 넘기고 HourlyReportFormatter 는 넘어온 정보를 출력한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| public class HourlyReporter {
private HourlyReportFormatter formatter;
private List<LineItem> page;
private final int PAGE_SIZE = 55;
public HourlyReporter(HourlyReportFormatter formatter) {
this.formatter = formatter;
page = new ArrayList<LineItem>();
}
public void generateReporter(List<HourlyEmployee> employees) {
for (HourlyEmployee e : employees) {
addLineItemToPage(e);
if (page.size() == PAGE_SIZE) {
printAndClearItemList();
}
}
if (page.size() == 0)
printAndClearItemList();
}
private void printAndClearItemList() {
formatter.format(page);
page.clear();
}
private void addLineItemToPage(HourlyEmployee e) {
LineItem item = new LineItem();
item.name = e.getName();
item.hours = e.getTenthsWorked() / 10;
item.tenths = e.getTenthsWorked() % 10;
page.add(item);
}
private class LineItem {
public String name;
public int hours;
public int tenths;
}
}
|
- 해당 코드에서 PAGE_SIZE라는 상수를 통해 논리적 의존성을 가진다.
- 해당 상수는 HourlyReporter 클래스는 HourlyReportFormatter 클래스가 페이지 크기를 알 것이라고 가정한다. 이러한 가정을 논리적 의존성이라고 하는데 이때 HourlyReportFormatter 가 페이지 크기를 처리하지 못한다면 오류가 발생하게 된다.
- 이를 해결하고자 HourlyReportFormatter 에 getMaxPageSize() 메서드를 추가하게 되면 위와 같은 논리적 의존성이 물리적 의존성으로 변환된다. 그래서 상수 대신 함수를 이용하여 논리적 의존성으로 인한 문제 대신 물리적 의존성 갖도록 변환해준다.
G23: If/Else 혹은 Switch/Case 문보다 다형성을 사용하라
- 대다수 개발자가 switch 문을 사용하는 이유는 올바르기보다는 손쉬운 선택이기 때문이다. 그러므로 switch를 선택하기 전에 다형성을 먼저 고려하라는 의미다.
- 유형보다 함수가 더 쉽게 변하는 경우는 극히 드물다. 그러므로 모든 switch 문을 의심해야 한다.
- 선택 유형 하나에는 switch 문을 한번만 사용하고, 같은 선택을 수행하는 다른 코드에서는 다형성 객체를 생성해 switch 문을 대신한다.
G24: 표준 표기법을 따르라
- 인스턴스 변수 선언 위치, 이름을 정하는 방법, 괄호를 넣는 위치 등에 대한 구현 표준을 따라야 한다.
- 이는 코드 자체로 충분해야 하며 별도의 문서로 설명할 필요가 없어야 하며 이렇게 정한 표준은 모든 팀원이 따라야 한다.
- 저자가 따르는 표기법이 궁금하다면 512쪽 목록 B-7에서 목록 B-14까지 제시한 코드를 살펴본다.
G25: 매직 숫자는 명명된 상수로 교체하라
- 일반적으로 코드에서 숫자를 직접 사용하지 말라는 규칙이며 이는 숫자를 명명된 상수 뒤로 숨기는 것을 의미한다.
- 예를 들어, 86,400 이라는 숫자는 SECONDS_PER_DAY 라는 상수 뒤로 숨긴다. 쪽당 55줄을 인쇄한다면 숫자 55는 LINES_PER_PAGE 상수 뒤로 숨긴다.
- 하지만 어떤 상수는 이해하기 쉬우므로 코드 자체가 자명하다면, 상수 뒤로 숨길 필요가 없다.
1
2
| double milesWalked = feetWalked/5280.0;
int dailyPay = hourlyRate * 8;
|
- 5280 은 마일당 피트에 대한 수치로 너무 잘 알려진 고유 숫자이다.
- 너무나도 잘 알려진 고유 숫자라면 주변 코드 없이 숫자만 달랑 적어놔도 독자가 금방 알아본다.
G26: 정확하라
검색 결과 중 첫 번째 결과만 유일한 결과로 간주, 부동소수점으로 통화를 표현, List로 선언할 변수를 ArrayList로 선언, 모든 변수를 protected 로 선언 하는것은 부정확한 방법이다.- 코드에서 무언가를 결정할땐 정확하게 결정해야 한다. 결정을 내리는 이유와 예외를 처리할 방법을 분명히 알아야 한다.
- null을 반환할 수 있는 함수는 반드시 null 체크를 하고, 조회 결과가 하나 뿐이라 짐작한다면 하나인지 확실히 확인한다.
- 코드에서 모호성과 부정확은 의견차나 게으름의 결과이고 어느 쪽이든 제거해야 마땅하다.
G27: 관례보다 구조를 사용하라
- 설계 결정을 강제할 때는 규칙보다 관례를 사용한다. 명명 관례도 좋지만 구조 자체로 강제하면 더 좋다.
- 예를 들어, enum 변수가 멋진 switch/case 문보다 추상 메서드가 있는 기초 클래스가 더 좋다.
- switch/case 문을 매번 똑같이 구현하게 강제하기는 어렵지만, 추상 메서드가 정의되어 있으면 해당 추상 클래스를 상속받는 파생 클래스는 해당 메서드를 모두 구현하지 않으면 안 되기 때문이다.
G28: 조건을 캡슐화하라
= 부울 논리는 이해하기 어렵기에 조건의 의도를 분명히 밝히는 함수로 표현하라
1
2
3
| if (shouldBeDeleted(timer)) // good
if (timer.haseExpired() && !timer.isRecurrent()) // bad
|
G29: 부정 조건은 피하라
- 부정 조건은 긍정 조건보다 이해하기 어렵다. 가능하면 긍정 조건을 표현한다.
1
2
3
| if (buffer.shouldCompact()) // good
if (!buffer.shouldNotCompact()) // bad
|
G30: 함수는 한 가지만 해야 한다.
- 한 함수 안에 여러 단락을 이어, 일련의 작업을 수행하고픈 유혹에 빠지는데 이런 함수는 한 가지만 수행하는 함수가 아니다.
- 함수는 한 가지 기능만을 해야하기에 좀 더 작은 함수 여럿으로 나눠야 마땅하다.
1
2
3
4
5
6
7
8
| public void pay(){
for (Employee e : employees) {
if (e.isPaypay()) {
Money pay = e.calculatePay();
e.deliverPay(pay);
}
}
}
|
- 위 코드는 세 가지 임무를 수행한다.
- 1)직원 목록을 루프 돌기
- 2)각 직원의 월급일을 확인
- 3)해당 직원에게 월급 지급
- 위 함수는 다음 함수 셋으로 나누는 편이 좋다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public void pay(){
for (Employee e : employees)
payIfNecessary(e); // 만약 필요하다면 지불하라
}
private void payIfNecessary(Employee e) {
if(e.isPayday()){
calculateAndDeliverPay(e); // 월급을 계산하고 전달하라
}
}
private void calculateAndDeliverPay(Employee e) {
Money pay = e.calculatePay();
e.deliverPay(pay);
}
|
- 위에서 각 함수는 한 가지 임무만 수행한다. (자세한 내용은 3장 “한 가지만 해라”를 참조한다.)
G31: 숨겨진 시간적인 결합
- 때로는 시간적인 결합이 필요하다. 하지만 시간적인 결합을 숨겨서는 안 된다.
- 함수 인수를 적절히 배치해 함수가 호출되는 순서를 명백히 드러내야 한다.
1
2
3
4
5
6
7
8
9
10
11
| public class MoogDiver {
Gradient gradient;
List<Spline> splines;
public void dive(String reason) {
saturateGradient();
reticulateSplines();
diveForMoog(reason);
}
...
}
|
- 세 함수가 순서대로 실행되는것이 목적이지만, 프로그래머가 reticulateSplines 를 먼저 호출하고 saturateGradient 을 호출하는 경우 발생하는 오류를 막을 수 없다.
- 따라서 실행 순서를 명확하게 표현할 수 있도록 아래와 같이 수정한다.
1
2
3
4
5
6
7
8
9
10
11
| public class MoogDiver {
Gradient gradient;
List<Spline> splines;
public void dive(String reason) {
Gradient gradient = saturateGradient();
List<Spline> splines = reticulateSplines(gradient);
diveForMoog(splines, reason);
}
...
}
|
- 위 코드는 일종의 연결 소자를 생성하여 시간적 결합을 노출한다. 각 함수가 내놓는 결과는 다음 함수에 필요하므로 순서를 바꿔 호출할수가 없게된다.
- 함수가 복잡해질수도 있다. 하지만 의도적으로 추가한 구문적인 복잡성이 원래 있던 시간적인 복잡성을 드러낸셈이다.
- 해당 클래스의 private 메서드에 필요한 변수일지도 몰
G32: 일관성을 유지하라
- 코드 구조를 잡을 때는 이유를 고민하고 그 이유를 코드 구조로 명백히 표현하라.
- 구조에 일관성이 없어 보인다면 남들이 맘대로 바꿔도 좋다고 생각하고, 시스템 전반에 걸쳐 구조가 일관성 있다면 남들도 일관성을 따르고 보존한다.
G33: 경계 조건을 캡슐화하라
- 경계 조건은 여기저기 처리하지 않고 한곳에서 별도 처리한다.
- 코드 여기저기에 +1 이나 -1을 흩어놓지 않는다.
1
2
3
4
| if (level + 1 < tags.length) {
parts = new Parse(body, tags, level + 1, offset + endTag;
body = null;
}
|
- 위 코드에서 level + 1 이 두 번 나오기 때문에 변수(nextLevel)로 캡슐화하는 것이 좋다.
1
2
3
4
5
| int nextLevel = level + 1;
if (nextLevel < tags.length) {
parts = new Parse(body, tags, nextLevel, offset + endTag;
body = null;
}
|
G34: 함수는 추상화 수준을 한 단계만 내려가야 한다
- 함수내 모든 문장은 추상화 수준이 동일해야 한다. 그리고 그 추상화 수준은 함수 이름이 의미하는 작업보다 한 단계만 낮아야 한다.
1
2
3
4
5
6
7
8
| public String render() throws Exception {
StringBuffer html = new StringBuffer("<hr");
if(size > 0)
html.append(" size=\"").append(size + 1).append("\"");
html.append(">");
return html.toString();
}
|
- 위 함수는 페이지를 가로질러 수평자를 만드는 HTML 태그를 생성한다. 수평자 높이는 size 변수로 지정한다.
- 여기서 추상화 수준은 여러개 섞여있다.
- 1)수평선에 크기가 있다.
- 2)HR 태그로 변환시 4개 이상의 연이은 ‘-‘ 기호를 감지해 HR 태그로 변환한다.
1
2
3
4
5
6
7
8
9
10
11
| public String render() throws Exception {
HtmlTag hr = new HtmlTag("hr");
if (extraDashes > 0)
hr.addAttributes("size", hrSize(extraDashes));
return hr.html();
}
private String hrSize(int height) {
int hrSize = height + 1;
return String.format("%d", hrSize);
}
|
- 위와 같이 추상화 수준을 분리해야 한다.
- size 변수는 추가된 대시의 개수를 저장하고, render 함수는 HR 태그만 생성한다. HTML HR 태그 문법은 HTMLTag 모듈이 처리해준다.
- 추상화 수준 분리는 리팩터링을 수행하는 가장 중요한 이유 중 하나고 제대로 하기에 가장 어려운 작업 중 하나이기도 하다.
G35: 설정 정보는 최상위 단계에 둬라
- 추상화 최상위 단계에 더야할 기본값 상수나 설정 관련 상수를 저차원 함수에 숨겨선 안된다.
- 대신 고차원 함수에서 저차원 함수를 호출시 인수로 넘긴다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public static void main(String[] args) throws Exception
{
Arguments arguments = parseCommandLine(args);
...
}
public class Arguments
{
public static final String DEFAULT_PATH = ".";
public static final String DEFAULT_ROOT = "FitNesseRoot";
public static final int DEFAULT_PORT = 80;
public static final int DEFAULT_VERSION_DAYS = 14;
...
}
|
- 디폴트 port 를 찾기 위해 저수준 함수들을 뒤지며 아래와 같은 코드를 발견하게 해선 안된다.
1
| if (arguments.port == 0) // 기본값으로 80을 사용한다.
|
- 설정 관련 상수는 최상위 단계에 둔다. 그래야 변경도 쉽다.
- 설정 관련 변수는 나머지 코드에 인수로 넘긴다. 저차원 함수에 상수 값을 정의하면 안된다.
G36: 추이적 탐색을 피하라
- 일반적으로 한 모듈은 주변 모듈을 모를수록 좋다. 좀 더 구체적으로 A가 B를 사용하고 B가 C를 사용한다 하더라도 A가 C를 알아야 할 필요는 없다는 뜻이다.(예를 들어 a.getB().getC().doSomething();은 바람직하지 안다)
- 즉, 자신이 직접 사용하는 모듈만 알아야한다. 이를 디미터의 법칙(Law of Demeter)이라 부른다.
- 여러 모듈에서
a.getB().getC()라는 형태를 사용한다면 설계와 아키텍처를 바꿔 B와 C사이에 Q를 넣기 쉽지 않다. a.getB().getC()를 모두 찾아 a.getB().getQ().getC()로 모두 바꿔야 하니깐… 너무 많은 모듈이 아키텍처를 너무 많이 알게 되고 아키텍처는 굳어지게 된다. - 즉, 원하는 메서드를 찾느라 객체 그래프를 따라 시스템을 탐색할 필요가 없어야 한다. 다시 말해 다음과 같은 간단한 코드로 충분해야 한다.
1
| myCollaborator.doSomething();
|
자바
J1: 긴 import 목록을 피하고 와일드카드를 사용하라
- 패키지에서 클랫스를 둘 이상 사용한다면 와일드 카드를 사용해 패키지 전체를 가져오라.
- 긴 import 문은 읽기 부담스럽다. 긴 import 문으로 모듈 상단을 채우고 싶진 않을것이다.
- 명시적인 import 문은 강한 의존성을 생성하지만 와일드카드는 그렇지 않다. 명시적으로 클래스를 import 하면 그 클래스가 반드시 존재해야 한다. 하지만 와일드카드로 패키지를 지정하면 특정 클래스가 존재할 필요는 없다. import 문은 패키지를 단순히 검색 경로에 추가하므로 진정한 의존성이 생기지 않는다. 그러므로 모듈 간에 결합성이 낮아진다.
- 하지만 요즘 인텔리제이와 같은 IDE 에선 import 영역을 자동으로 가려주며 필요시에만 확장해볼수있도록 해주고 와일드카드 import 를 지양하라는 내용들을 많이 얘기하곤 한다. 그 이유는 다음과 같다.
- 1)런타임 성능에는 전혀 영향을 주지 않지만, 컴파일 성능에 안좋은 영향이 있을수 있다.(참고)
- 2)같은 이름을 가진 다른 패키지의 클래스가 존재 할 때 충돌을 야기할 수 있다.
- 3)어떤 클래스에서 실제 import 한것인지 혼란을 야기할 수 있다.
- 4)명시적인 import의 장점을 놓칠수 있다. 명시적인 import는 어떠한 클래스를 import하는지 명시적으로 드러내므로 코드에서 중복되는 import를 피할 수 있다.
- 관련하여 아래 포스팅을 참고하면 좋다.
J2: 상수는 상속하지 않는다
- 아래 클래스에서 사용하는 TENTHS_PER_WEEK 와 OVERTIME_RATE 상수의 출처는 어디일까?
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class HourlyEmployee extends Employee {
private int tenthsWorked;
private double hourlyRate;
public Money calculatePay() {
int straightTime = Math.min(tenthsWorked, TENTHS_PER_WEEK);
int overTime = tenthsWorked - straightTime;
return new Money(
hourlyRate * (tenthsWorked + OVERTIME_RATE * overTime)
);
}
...
}
|
1
2
3
4
5
| public abstract class Employee implements PayrollConstants {
public abstract boolean isPayday();
public abstract Money calculatePay();
public abstract void deliverPay(Money pay);
}
|
- 해당 클래스에도 상수는 존재하지 않는다. 그렇다면 PayrollConstants 인터페이스를 살펴보자.
1
2
3
4
| public interface PayrollConstants {
public static final int TENTHS_PER_WEEK = 400;
public static final double OVERTIME_RATE = 1.5;
}
|
- 상수를 상속 계층 맨 위에 숨겨놨따. 상속을 이렇게 사용하면 안되고 언어의 범위 규칙을 속위는 행위이다.
- 대신 static import 를 사용하라
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import static PayrollConstants.*;
public class HourlyEmployee extends Employee {
private int tenthsWorked;
private double hourlyRate;
public Money calculatePay() {
int straightTime = Math.min(tenthsWorked, TENTHS_PER_WEEK);
int overTime = tenthsWorked - straightTime;
return new Money(
hourlyRate * (tenthsWorked + OVERTIME_RATE * overTime)
);
}
...
}
|
J3: 상수 대 Enum
- public static final int 라는 옛날 기교를 더 이상 사용할 필요가 없다. enum 을 마음껏 활용하라!
- int 는 코드에서 의미를 잃어버리기도 한다.
- enum은 이름이 부여된 열거체(enumeration)에 속하고 int 보다 훨씬 더 유연하고 서술적인 강력한 도구다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| public class HourlyEmployee extends Employee {
private int tenthsWorked;
HourlyPayGrade grade; // 객체 생성
public Money calculatePay() {
int straightTime = Math.min(tenthsWorked, TENTHS_PER_WEEK);
int overTime = tenthsWorked - straightTime;
return new Money(
grade.rate() * (tenthsWorked + OVERTIME_RATE * overTime) // enum에서 rate()함수의 return 값 가져옴
);
}
}
public enum HourlyPayGrade {
APPRENTICE {
public double rate() {
return 1.0;
}
},
LIEUTENANT_JOURNEYMAN {
public double rate() {
return 1.2;
}
},
JOURNEYMAN {
public double rate() {
return 1.5;
}
},
MASTER {
public double rate() {
return 2.0;
}
};
public abstract double rate();
}
|
이름
N1: 서술적인 이름을 사용하라
- 서술적인 이름을 신중하게 골라라. 소프트웨어가 진화하면 의미도 변하므로 선택한 이름이 적합한지 자주 되돌아본다.
- 소프트웨어 가독성의 90%는 이름이 결정한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| // 미지의 숫자와 기호가 뒤섞인 의도가 드러나지 않는 잡탕 코드
public int x() {
int q = 0;
int z = 0;
for (int kk = 0; kk < 10; kk++) {
if (l[z] == 10)
{
q += 10 + (l[z + 1] + l[z + 2]);
z += 1;
}
else if (l[z] + l[z + 1] == 10)
{
q += 10 + l[z + 2];
z += 2;
} else {
q += l[z] + l[z + 1];
z +=2;
}
}
return q;
}
// 아직 미완성이더라도 의도가 드러나는 서술적인 구조의 코드
public int score() {
int score = 0;
int frame = 0;
for (int frameNumber = 0; frameNumber < 10; frameNumber++) {
if (isStrike(frame)) {
score += 10 + nextTwoBallsForStrike(frame);
frame += 1;
}
else if (isSpare(frame)) {
score += 10 + nextBallForSpare(frame);
frame += 2;
} else {
score += twoBallsInFrame(frame);
frame += 2;
}
}
return score;
}
|
N2: 적절한 추상화 수준에서 이름을 선택하라
- 구현을 드러내는 이름을 피하라. 작업 대상 클래스나 함수가 위치하는 추상화 수준을 반영하는 이름을 선택하라. 쉽지 않은 작업이다.
1
2
3
4
5
6
7
| public interface Modem {
boolean dial(String phoneNumber); // phoneNumber 라는 구현을 드러내는 변수명
boolean disconnect();
boolean send(char c);
char recv();
String getConnectedPhoneNumber() // phoneNumber 라는 구현을 드러내는 함수명
}
|
- 만약 전화선에 연결되지 않는 일부 모뎀을 사용하는 애플리케이션을 생각해보자(요즘 대다수 가정에서 사용하는 케이블 모뎀처럼). 전용선을 사용하는 모뎀을 고려해보라. 일부는 USB로 연결된 스위치에 포트 번호를 보낼지도 모른다.
전화번호라는 개념은 확실히 추상화 수준이 틀렸다. 더 좋은 ‘이름 선택’ 전략은 다음과 같다.
1
2
3
4
5
6
7
| public interface Modem {
boolean connect(String connectionLocator); // connectionLocator 로 추상화 수준에 맞는 변수명
boolean disconnect();
boolean send(char c);
char recv();
String getConnectedLocator(); // connectionLocator 로 추상화 수준에 맞는 함수명
}
|
- 위 코드는 연결 대상의 이름을 더 이상 전화번호로 제한하지 않는다. 전화번호는 물론이고 다른 연결 방식에도 사용 가능하다.
N3: 가능하다면 표준 명명법을 사용하라
- 더 이해하기 쉽다. 예를 들어, DECORATOR 패턴을 활용한다면 장식하는 클래스 이름에 Decorator 라는 단어를 사용해야 한다.
- 예를 들어, AutoHangupModemDecorator 는 세션 끝 무렵에 자동으로 연결을 끊는 기능으로 Modem 을 장식하는 클래스 이름에 적합하다.
- 패턴은 한 가지 표준에 불과하다. 자바에서 객체를 문자열로 변환하는 함수는 toString 이라는 이름을 많이 쓴다. 이런 이름은 관례를 따르는 편이 좋다.
- 흔히 팀마다 특정 프로젝트에 적용할 표준을 나름대로 고안한다. 에릭 에반스(Eric Evans)는 이를 프로젝트의 유비쿼터스 언어라 부른다. 코드는 이 언어에 속하는 용어를 열심히 써야 프로젝트의 전체적인 가독성이 좋아지게 된다.
N4: 명확한 이름
- 함수나 변수의 목적을 명확히 밝히는 이름을 선택한다.
1
2
3
4
5
6
7
8
9
10
| private String doRename() throws Exception
{
if(refactorReferences)
renameReferences();
renamePage();
pathToRename.removeNameFromEnd();
pathToRename.addNameToEnd();
return PathParser.render(pathToRename);
}
|
- 이름만 봐선 함수가 하는 일이 분명하지 않다. 아주 광범위하며 모호하다. doRename 함수 안에 renamePage 라는 함수가 있어 더더욱 모호하다. 이름만으로도 두 함수 사이의 차이점이 드러나는가? 전혀 아니다.
- renamePageAndOptionallyAllReferences라는 이름이 더 좋다. 이렇게 하면 이름이 길어진다는 단점을 가지지만, 서술성이 충분히 이 단점을 매꾼다.
N5: 긴 범위는 긴 이름을 사용하라
- 이름 길이는 범위 길이에 비례해야 한다.
- 범위가 작으면 아주 짧은 이름을 사용해도 괜찮다. 하지만 범위가 길어지면 긴 이름을 사용한다.
- 범위가 5줄 안팎이라면 i나 j와 같은 변수명도 괜찮다. 다음은 전통적인 ‘볼링 게임’ 에서 가져온 코드다.
1
2
3
4
5
| private void rollMany(int n, int pins)
{
for (int i=0; i<n; i++)
g.roll(pins);
}
|
- 오히려 변수 i를 rollCount라 썼다면 헷갈릴 터이다.
- 반면, 이름이 짧은 변수나 함수는 범위가 길어지면 의미를 잃는다. 그러므로 이름 범위가 길수록 이름을 정확하고 길게 짓는다.
N6: 인코딩을 피하라
- 이름에 유형 정보나 범위 정보를 넣어선 안된다.
- 오늘날 개발 환경에서는 이름 앞에 m_이나 f와 같은 접두어는 중복된 정보를 나타내기에 지양해야 한다.
N7: 이름으로 부수 효과를 설명하라
- 함수, 변수, 클래스가 하는 일을 모두 기술하는 이름을 사용한다. 이름에 부수 효과를 숨기지 않는다.
- 실제로 여러 작업을 수행하는 함수에다 동사 하나만 달랑 사용하면 곤란하다.
1
2
3
4
5
6
| public ObjectOutputStream getOos() throws IOException {
if (m_oos == null) {
m_oos = new ObjectOutputStream(m_socket.getOutputStream());
}
return m_oos;
}
|
- 위 함수는 단순히 ‘oos’ 만 가져오지 않는다. 없으면 if 조건문을 통해 생성해준다. 그러므로 createOrReturnOos라는 이름이 더 좋다.
테스트
T1: 불충분한 테스트
- 테스트 케이스는 잠재적으로 깨질만한 부분을 모두 테스트해야 한다.
- 테스트 케이스가 확인하지 않는 조건이나 검증하지 않는 계산이 있다면 그 테스트는 불완전하다.
T2: 커버리지 도구를 사용하라!
- 커버리지 도구는 테스트가 빠뜨리는 공백을 알려준다.
- 대다수 IDE는 테스트 커버리지를 시각적으로 표현한다.
T3: 사소한 테스트를 건너 뛰지마라
- 사소한 테스트는 짜기 쉽다. 사소한 테스트가 제공하는 문서적 가치는 구현에 드는 비용을 넘어선다.
T4: 무시한 테스트는 모호함을 뜻한다.
- 때로는 요구사항이 불분명하기에 프로그램이 돌아가는 방식을 확신하기 어렵다.
- 불분명한 요구사항은 테스트 케이스를 주석으로 처리하거나 테스트 케이스에 @Ignore를 붙여 표현한다.
- 불분명한 요구사항을 판별하는 기준은 테스트 케이스의 컴파일 가능 여부에 달려있다.
T5: 경계 조건을 테스트하라
- 경계 조건은 각별히 신경 써서 테스트해야한다. 알고리즘의 중앙 조건은 올바로 짜놓고 경계 조건에서 실수하는 경우가 흔하다.
T6: 버그 주변은 철저히 테스트하라
- 버그는 서로 모이는 경향이 있다. 한 함수에서 버그를 발견했다면 그 함수를 철저히 테스트하는 편이 좋다. 십중팔구 다른 버그도 발견하게 될것이다.
T7: 실패 패턴을 살펴라
- 테스트 케이스가 실패하는 패턴으로 문제를 진단할 수 있다. 테스트 케이스를 최대한 꼼꼼히 짜라는 이유도 여기에 있다.
T8: 테스트 커버리지 패턴을 살펴라
- 통과하는 테스트가 실행하거나 실행하지 않는 코드를 살펴보면 실패하는 테스트 케이스의 실패 원인이 드러난다.
T9: 테스트는 빨라야 한다
- 느린 테스트 케이스는 실행하지 않게 된다.
- 일정이 촉박하면 느린 테스트 케이스를 제일 먼저 건너뛰게 된다.
- 그러므로 테스트 케이스가 빨리 돌아가게 최대한 노력한다.
결론
- 이 장에서 소개한 휴리스틱과 냄새 목록이 완전하다 말하기는 어렵다. 아니, 완전한 목록이 가능하다고도 저자는 생각하지 않는다. 하지만 완전한 목록이 목표가 아니고 여기서 소개한 목록은 가치 체계를 피력할 뿐인다.
- 사실상 가치 체계는 이 책의 주제이자 목표다. 일군의 규칙만 따른다고 깨끗한 코드가 얻어지지 않는다. 휴리스틱 목록을 익힌다고 소프트웨어 장인이 되지는 못한다. 전문가 정신과 장인 정신은 가치에서 나온다. 그 가치에 기반한 규율과 절제가 필요하다.
Reference